What is the FDAT research data repository?
Institutional Affiliation: FDAT is the institutional research data repository of the University of Tübingen and is operated by the Digital Humanities Center.
Primary Objective: The purpose of FDAT is to provide a long-term archiving and public dissemination service for research data.
Management and Oversight: The Knowledge Media Research Center (IKM) is responsible for the oversight and management of FDAT, ensuring its efficient operation and adherence to academic standards.
Targeted Research Fields: While FDAT is an inclusive service open to researchers from all scientific disciplines at the University of Tübingen, there is a particular focus on supporting the humanities and social sciences.
Commitment to FAIR Principles: FDAT adheres to the FAIR guiding principles, aiming to ensure the findability, accessibility, interoperability, and reusability of its archived research data.
Commitment to Good Research Practice: FDAT is committed to enabling the DFG's Guidelines for Safeguarding Good Research Practice for research data, which emphasise on the public accessibility of archived and identifiable data for the in repository systems for a period of at least ten years.
Commitment to Open Access: FDAT is committed to the University of Tübingen's Open Access policy for research data, which emphasises transparency of research, reproducibility, and wider dissemination of knowledge among the public.
Technical Foundation: The technical framework of FDAT is derived from the open-source repository software InvenioRDM.
Who should make use of the FDAT repository?
As a researcher at the University of Tübingen, you might want to consider the FDAT repository for archiving and publishing your research data, particularly if you do not have access to discipline-specific repositories for that purpose. As an institutional repository, FDAT is not designed to meet the discipline-specific requirements of data management, processing and presentation that might be preferable or necessary for your type of data. As an alternative to FDAT, re3data provides a comprehensive directory to find discipline-specific research data repositories.
How is FDAT embedded into the university infrastructure?
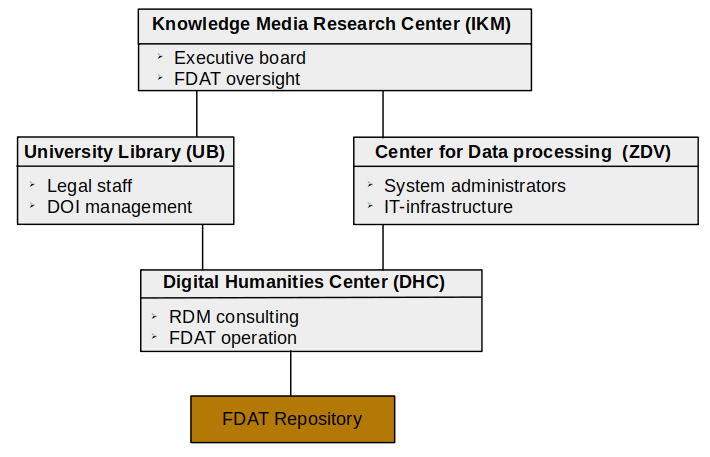
What are the core features of FDAT?
Continuous Development: FDAT is based on the InvenioRDM data management software, which has been continuously developed under the direction of CERN.
Preservation and Longevity: FDAT provides long-term safeguarding of research data, protected against unauthorized interventions or modifications, employing robust backup strategies and geo-redundant storage.
Scalability: FDAT is capable of handling large amounts of data and records. It can scale from a few records to millions and from small data volumes to several petabytes.
Persistent Identifiers: FDAT assigns a Digital Object Identifier (DOI) to each record, ensuring unambiguous identifiability and increasing the potential for scholarly citation.
Visibility and Accessibility: Data hosted in FDAT gains increased visibility within the academic community and the general public, potentially increasing citation rates and enhancing academic impact.
Search Capabilities: FDAT utilizes a powerful search engine to support complex search queries, sorting, and filtering options to help users quickly find the data they need.
Data Management Tools: FDAT provides services for efficient data management, including metadata annotation and versioning capabilities.
Data Integrity: Multiple quality control measures are implemented to maintain the reliability and integrity of stored data.
Collaboration: FDAT allows researchers to create communities, collaborate with scientists and publish within their field of science.
Fast Publication: FDAT ensures rapid publication of data through the registration of DOIs immediately upon data upload.
Access Controls: FDAT allows for selective data sharing, such as allowing anonymised data to be shared with specific groups of people.
Dataset Version Control: The inherent versioning system of FDAT facilitates the seamless updating and iteration of datasets.
What type of content can be published in FDAT?
FDAT is dedicated to the dissemination of primary research data that underpin scientific studies. Accordingly, only well-documented datasets, including raw, processed or derived data files or research software, accompanied by appropriate metadata, may be deposited. Any other form of scholarly communication, such as manuscripts, preprints, published articles, theses, book chapters, conference papers, posters or presentations are not accepted for publication in FDAT. Please contact the University Library or the Tübingen University Press instead. Those interested in publishing open educational resources (OER) can use the state-operated ZOERR repository as a dedicated platform.
Is there a charge for accessing and/or depositing data in FDAT?
Access to Datasets: Datasets in FDAT can be accessed free of charge.
Data storage < 1 TB: Data from research projects at the University of Tübingen can be deposited in FDAT free of charge.
Data storage > 1 TB: For large quantities of data to be uploaded to FDAT in excess of 1TB, the storage capacity of FDAT may need to be expanded, which requires lead time and potentially the application for a storage project. Fees may apply for large data ingestion or specialised data curation services to cover storage, processing and maintenance costs. Researchers may contact the Digital Humanities Center for more information on this topic.
Where to get support for any further questions about FDAT?
Hosting Institution: Digital Humanities Center
Administrator: Dr. Steve Kaminski
Phone: +49 (7071) 29-77848
What are the terms and conditions for submitting research data to FDAT?
The repository agreement outlines the terms and conditions for submitting research data to FDAT and can be found on the repository landing page (https://fdat.uni-tuebingen.de) as shown in Fig.1.
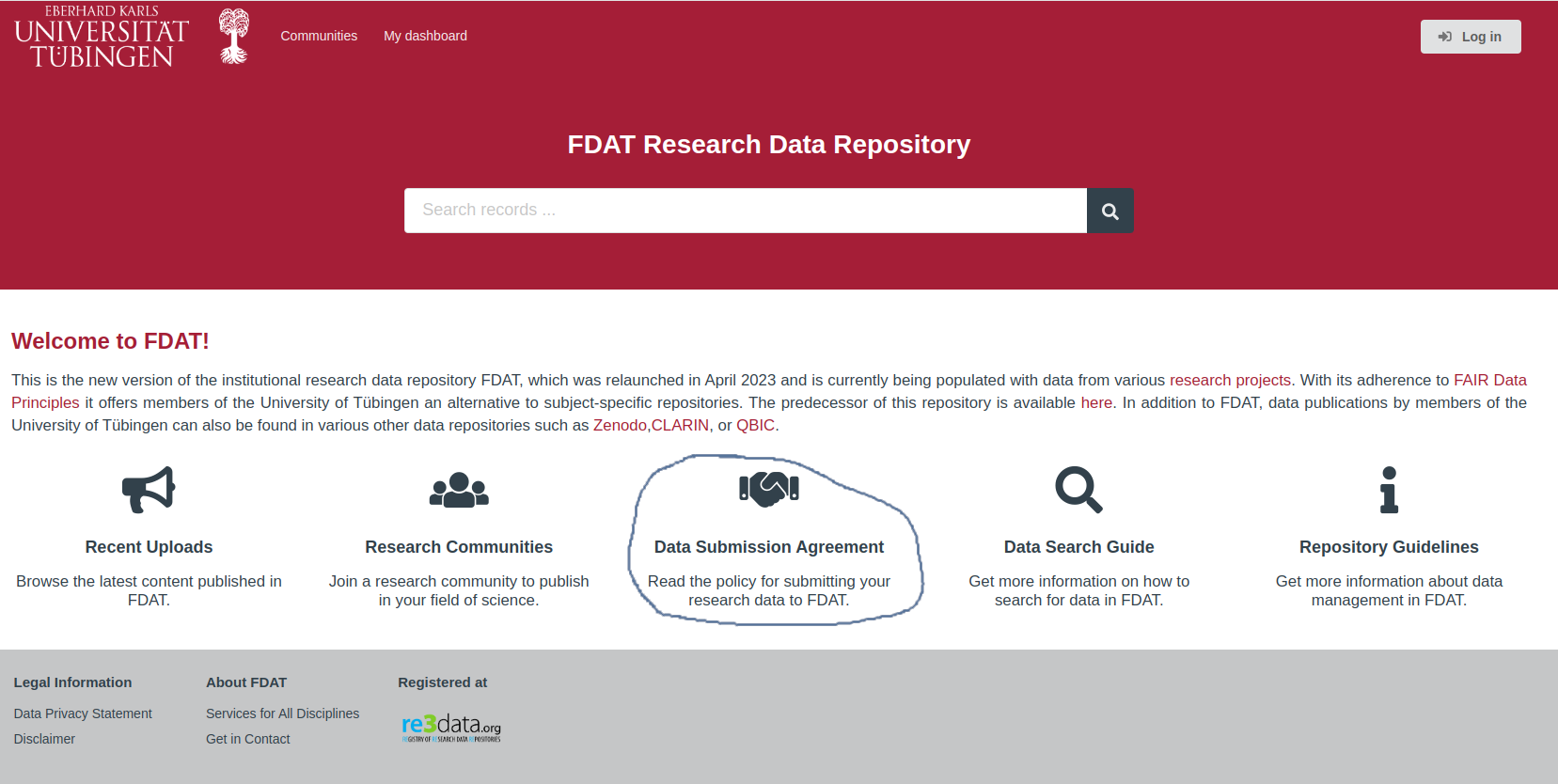
Potential users must read the full document and agree to the terms prior to submitting datasets to the FDAT repository for archiving and publication. Key points of the agreement include:
Obligations of the Repository Host
- Publish datasets with DOI for unambiguous referencing.
- Implement peer-reviewed data curation.
- Guarantee a 10-year retention period.
- Continually evolve and potentially replace the service.
- Apply bitstream preservation without altering data content.
- Ensure data preservation with geo-redundancy.
- Right to refuse or remove data if legally questionable.
Obligations of Data Providers
- Must hold usage rights and grant the repository a non-exclusive right to use, archive, migrate, and publish data.
- Take full responsibility for compliance with export control regulations (see also next section)
- Agree to publish metadata under a Creative Commons CC0 license.
- Ensure data legality, anonymity, and integrity.
- Be responsible for the completeness of the data and can request data withdrawal in exceptional cases.
Does your data comply with export control laws?
All researchers and data contributors must inform themselves about and take full responsibility for compliance with export control regulations when depositing data in this repository.
Export control laws apply to the sharing, transfer, and publication of research data, materials, software, and technical knowledge. The University of Tübingen has a broad international presence and therefore sometimes participates in foreign trade, which is subject to export control regulations. These regulations affect numerous university activities including international research collaborations, knowledge and data transfers, publications, and cooperation with international researchers.
Key Areas of Responsibility
Before depositing data in this repository, researchers must ensure compliance with export control regulations regarding:
- Data and Knowledge Transfer: Digital files, datasets, software, and technical documentation may be subject to export controls
- International Accessibility: Consider whether unrestricted access to your data could violate export control laws
- Dual-Use Materials: Research data that could have both civilian and military applications requires special consideration
- Sanctioned Entities: Ensure your data will not be accessible to individuals or institutions on sanctions lists
- Technical Assistance: Providing explanatory documentation or support materials may constitute controlled technical assistance
Legal Consequences
Violations of export control regulations are punishable by heavy fines or even imprisonment (up to 10 years) for individuals and heavy fines (up to 10 million euros, or more in some cases) for institutions of higher education. Both researchers and the University bear legal responsibility for compliance.
Required Actions
- Self-Assessment: Review your research data against relevant export control lists and regulations
- Seek Guidance: Consult with the University's export control office if you have any questions about your data's classification
- Documentation: Maintain records of your export control assessment process
- Ongoing Monitoring: Stay informed about changes to export control regulations that may affect your deposited data
Resources and Support
For detailed information about export controls in science and research, including practical guidance and training opportunities, visit: Export Controls in Science and Research
By depositing data in this repository, you confirm that you have reviewed applicable export control regulations and taken responsibility for ensuring compliance.
Is FDAT compliant with the FAIR guiding principles?
FDAT is designed to adhere to the FAIR (Findable, Accessible, Interoperable, and Reusable) principles. The platform not only ensures effective data management but also emphasizes the broader mission of making research data available to the research community and general public. Here's a detailed breakdown of how FDAT meets each of the FAIR principles:
Findable
DOIs: Through integration with DataCite, FDAT assigns a unique Digital Object Identifier to each dataset. This ensures that datasets are not only easily discoverable, but also persistently citable, regardless of changes in platform or dataset location.
Metadata: FDAT adopts the DataCite metadata schema, ensuring a standardized and descriptive approach to dataset indexing. Such standardized metadata enhances discoverability across all research data.
Search Capabilities: The advanced search engine capabilities of FDAT, including faceted searching and keyword highlighting, ensure that the datasets in FDAT can be easily found by researchers and by the general public.
Accessible
Controlled Access: FDAT understands the importance of controlled access to particularly sensitive data. Researchers have the flexibility to set access controls as required.
API Integration: FDAT's robust API allows for programmatic access to datasets, paving the way for automated data retrieval and integration with third-party platforms and tools.
User-friendly Interface: The FDAT interface is intuitive, ensuring that even those new to data repositories can access and navigate datasets with ease.
Interoperable
Standardized Metadata: FDAT's adherence to the DataCite metadata standards ensures that the data remains compatible across various platforms, promoting seamless data exchange and collaboration.
Varied Data Formats: The platform's support for a wide variety of file formats ensures that data can be shared, accessed, and used across a range of research tools and disciplines.
Linked Data: Where applicable, FDAT promotes the use of linked data principles, enhancing semantic interoperability and ensuring that datasets can be coherently integrated with external data sources.
Reusable
Clear Licensing: To promote data reuse, FDAT provides guidance on the selection of appropriate licences. Researchers are encouraged to use open licences to ensure that data is not only accessible but also reusable under clear, pre-defined terms.
Versioning: FDAT's built-in dataset versioning system ensures that researchers can make updates or corrections to their data, ensuring that the most accurate version is always available for reuse.
Data Quality: FDAT emphasises the importance of data quality. By providing tools for metadata annotation, quality control and dataset documentation, the platform ensures that data is not only reusable, but also reliable.
How is personal data protected in FDAT?
Secure Data Infrastructure: The FDAT repository database of personal and research data is part of the secure data infrastructure of the University's Center for Data Processing (ZDV), which protects against data loss and malicious attacks.
Federated Identity Management: FDAT uses the federated authentication system bwIDM as provided by the state of Baden-Württemberg, allowing users to authenticate through a centralized sign-on service via the identity provider of their affiliated research institution. As a result, user passwords are not stored in the repository database at any time, further enhancing personal data protection.
Encrypted Data Transfer: In FDAT, securing the transmission of personal and research data between the client browser (e.g., a researcher) and the server (FDAT repository) is crucial. HTTPS (Hypertext Transfer Protocol Secure) is employed to encrypt this communication, ensuring data security during transit. Using session keys, all data exchanged between the client and server is encrypted, ensuring it remains confidential and protected from interception.
Data Minimisation: FDAT adheres to the principle of data minimisation and only collects and stores the minimum amount of personal data necessary to fulfil its functions. In order to uniquely identify a user of the repository, to manage the user's access rights to research data, and to contact the user if necessary, the following personal data is requested from the user's institution's authentication server:
- Username
- Full name
- Affiliations
- Email address
Role-Based Access Control (RBAC): FDAT utilizes RBAC to ensure that only authorized individuals can access specific data. Access to personal data is restricted to system administrators and data owners. As shown in Fig.2, users in FDAT have roles assigned to their account, such as reader, curator, manager or owner, to regulate their access rights to specific research and personal data.
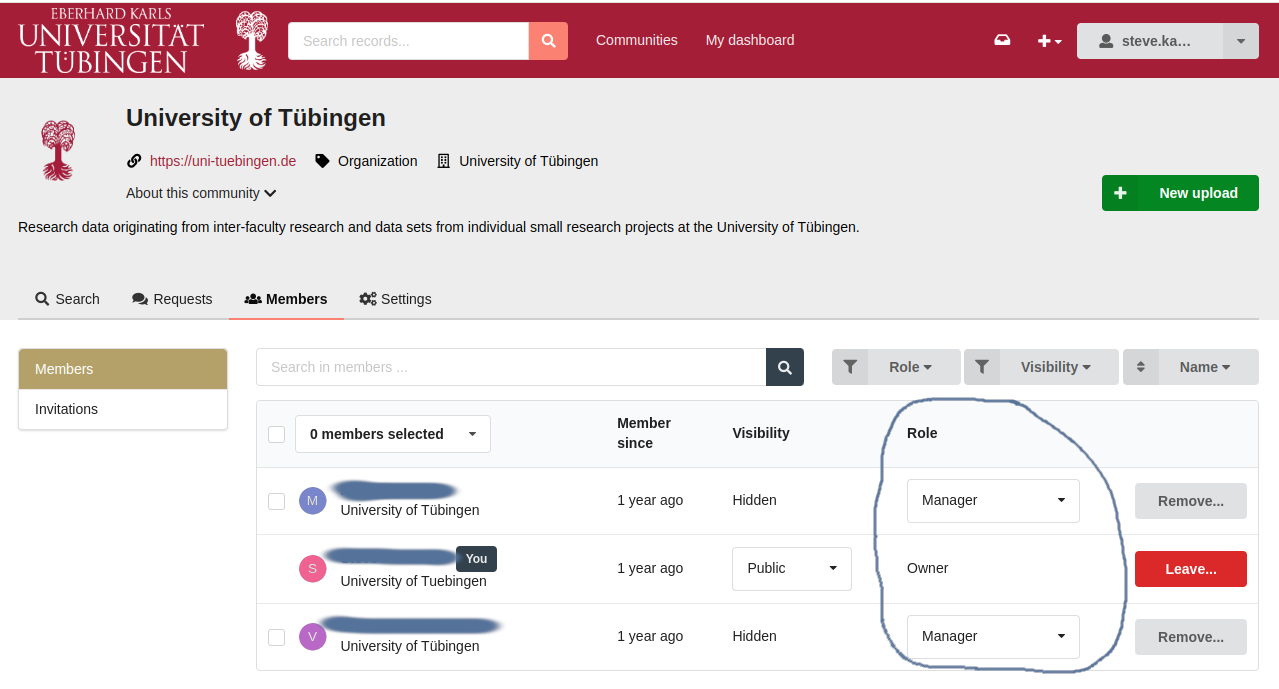
User Data Visibility in FDAT: In FDAT, registered users can choose whether or not to make their profile and email address visible to other users in the repository, as shown in Fig.3. This allows a degree of anonymity for the user's actions and existence in the repository.
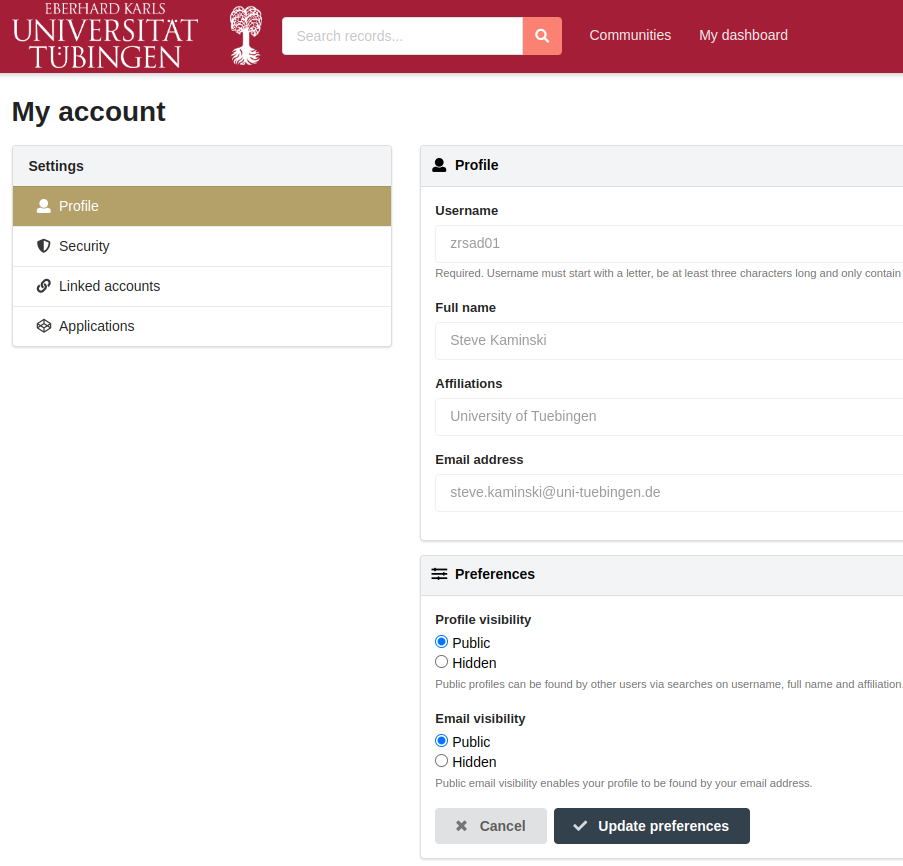
Transmitted Personal Data to FDAT: When users log in to FDAT via their Institutional Member (IdP), they will be given an overview of all their personal data (username, name, email, ... / upper half in Fig.4) that the IdP is sending to FDAT, which can vary greatly between IdPs. Users should carefully consider whether they agree with the amount of data sent to FDAT, and can choose whether their IdP should automatically send this data to FDAT during each login process, or whether this information should be re-checked by the user each time the user logs in.

What persistent identifier standards are used in FDAT?
Persistent Identifiers (PIDs) are critical tools for research repositories, enhancing the management, accessibility, and attribution of research outputs. By providing unique and permanent identifiers for various entities within the research ecosystem, PIDs ensure that data, researchers, and institutions can be reliably and consistently identified, tracked, and referenced. All PIDs system integrated into FDAT are listed and explained below.
DOI (Digital Object Identifier): FDAT incorporates the DOI system as provided by the non-profit organization DataCite to make research data permanently citable, recognising the widespread acceptance of DOI as a tool for identifying and citing research data.
ORCID (Open Researcher and Contributor ID): FDAT uses ORCID-IDs which provide unique identifiers for researchers, linking them with their work and ensuring proper attribution and recognition. This system helps in maintaining a comprehensive and accurate record of a researcher's contributions.
GND (The integrated authority file): GNDs are used for uniquely identifying researchers, facilitating accurate and consistent identification in library and academic contexts. This system helps in maintaining uniformity and accuracy in the cataloging of research outputs.
ROR (Research Organization Registry): ROR identifers are utilized in FDAT to provide unique identifiers for research organizations, offering a standardized way to identify institutions. This aids in the clear attribution of research affiliations and tracking of collaborations, ensuring that institutional contributions are properly recognized.
ISNI (International Standard Name Identifier): ISNI uniquely identifies researchers, disambiguating their identities and enhancing the integrity of author records. This is particularly useful in ensuring that publications and datasets are correctly attributed to the right individuals.
What metadata standards are used in FDAT?
FDAT employs several established metadata standards to ensure comprehensive and consistent documentation of datasets. These standards facilitate data discovery, interoperability, and reuse across various research domains. The primary metadata standards used in the FDAT repository are
- DataCite is used for general dataset description and citation and discovery.
- CodeMeta is applied to software and code associated with research datasets.
- Data Documentation Initiative (DDI) is used for detailed documentation of survey and observational data.
What are the standards for data quality control in FDAT?
Metadata Quality Control (Technical): Accurate and comprehensive metadata is essential for data retrieval and interpretation. Each dataset's metadata is evaluated for completeness and accuracy against the DataCite standard, as it is entered into the FDAT web interface. Errors are visually highlighted along with help text for each input field, as shown in Fig.5 and Fig.6.
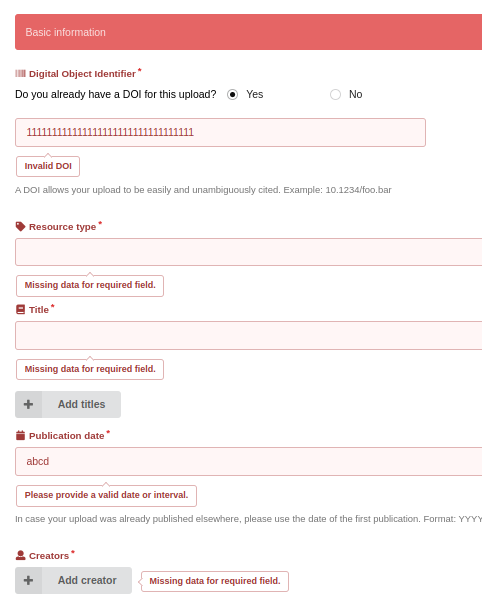
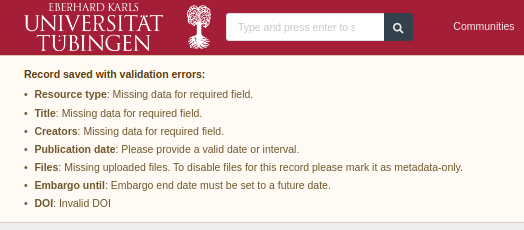
File Integrity Checks: During the file upload process, MD5 checksums are automatically generated by FDAT. The values are also stored in the FDAT database and will be regularly re-evaluated to ensure data integrity and immutability in the FDAT repository.
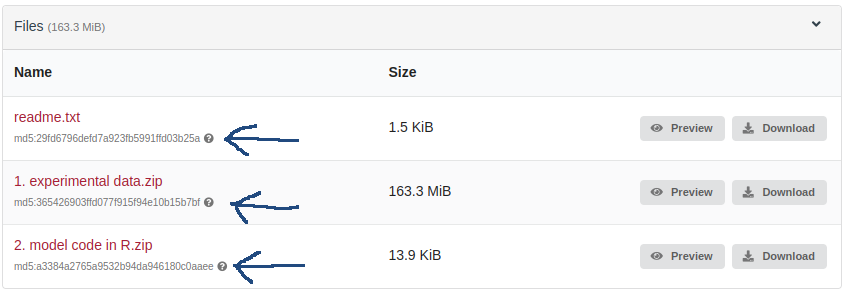
Data Content Quality Control:
In the context of research, data quality is of particular importance. Quality data ensures that research findings are based on sound, reliable, and accurate information, which in turn bolsters the credibility and reproducibility of research outcomes. Moreover, in a landscape where data sharing and collaboration are becoming increasingly common, having standardized and high-quality data is pivotal for interdisciplinary work and cross-institutional projects.
The FAIR (Findable, Accessible, Interoperable, and Reusable) principles serve to reinforce the significance of data quality. These principles are designed to ensure that research data is not merely stored, but is also easily discoverable, accessible, interoperable across different systems, and reusable for various purposes. Each of these FAIR dimensions inherently relies on high data quality, asi illustrated in Fig.8. For instance, for data to be 'Findable', its metadata must be accurate and complete. Similarly, the concept of interoperability is directly linked to the notion of data consistency and conformity to established standards.

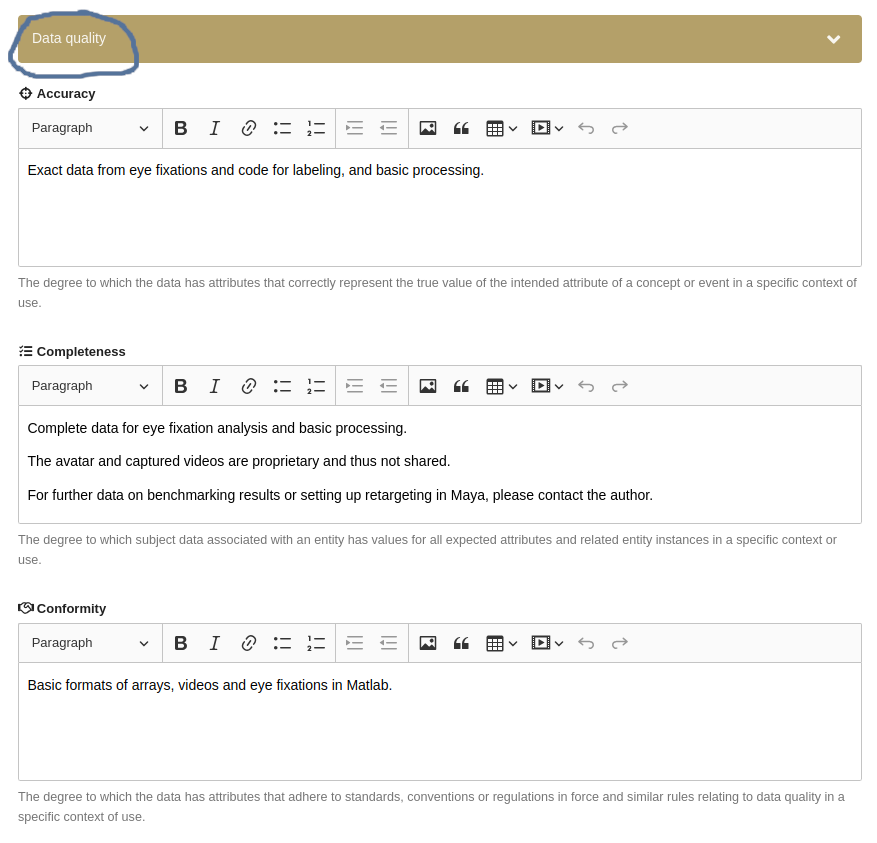
With this context in mind, FDAT's approach to ensuring data quality includes the following mandatory information from any data collection:
Accuracy: The exact means of measuring accuracy often depends on the use case. For example, in CSV files, each cell of a column could be assessed for accuracy against specific encoding formats, such as ISO 8601 for dates.
Completeness: Metadata is descriptive data. Essential metadata such as title, artist information, or album details enhance the completeness of a record.
Conformity/Compliance: Conformity ensures that data conforms to established standards. This can be particularly important for date formats, which can vary according to regional conventions. Community standards should be used to ensure conformity between datasets.
Consistency: Community standards play an important role in ensuring consistency between files and formats within a domain. Adherence to such standards streamlines data reuse, as all conforming data will have similarities in organisation, documentation structure or vocabulary.
Relevance: It's important to ensure that the data is relevant to the research question or topic with which it is associated.
Timeliness: Data and metadata in FDAT are expected to be up-to-date, representing the most recent and current situation. As changes occur in the real world, the data and metadata should be updated accordingly to maintain currency.
Understandability: Ensuring that data is understandable is critical. FDAT emphasises the provision of clear data descriptions and thorough documentation.
Periodic Audits: Regular audits of the repository ensure data consistency and integrity, identifying and addressing any emerging issues.
Collaboration with Data Stewards: For specific datasets or research projects, FDAT collaborates with the associated data stewards for data validation, ensuring the relevance and accuracy of the content.
What standard interfaces and data integration services does FDAT provide?
To facilitate data integration and the automation of various repository related tasks, FDAT offers a feature-rich API through InvenioRDM. Here's an overview of the features available:
RESTful API: FDAT provides a comprehensive RESTful API, that allows users to programmatically access, deposit, and manage datasets. This is particularly useful for integrating FDAT with other platforms or automating batch operations.
OAuth Support: FDAT supports OAuth, enabling third-party integration for secure delegated user authentication.
Data Harvesting: FDAT supports the OAI-PMH protocol, enabling standardised data harvesting. This is useful for aggregators or services that want to periodically retrieve and synchronise data from FDAT.
How does FDAT store data securely for the long term?
FDAT relies on the bwSFS storage infrastructure as the foundation for secure and durable data storage. This infrastructure is a collaborative effort between the universities of Tübingen, Freiburg, Stuttgart and Konstanz.

Sustainable Funding for bwSFS
DFG & MWK: A significant portion of the bwSFS funding comes from the DFG and the state-owned MWK. Both play a pivotal role in the funding of the infrastructure, with a particular emphasis on the long-term storage and provision aspects.
bwSFS Integration in FDAT
Security and Reliability: The use of bwSFS ensures that research data is stored in a secure environment, protected against potential breaches and data loss.
Data Availability and Redundancy: The bwSFS storage infrastructure is designed to provide enhanced data availability and redundancy, thereby ensuring uninterrupted data access even in the event of hardware failure or other unforeseen disruptions.
Long-Term Preservation: One of the key benefits of the bwSFS is the assurance of long-term preservation of research data, ensuring its accessibility and relevance for future research.
How is data structured and stored in FDAT?
Data Storage Technology
In FDAT, research data files are stored utilizing an S3 object storage system, which provides a robust and scalable solution for managing large volumes of research data. The S3 (Simple Storage Service) model operates by organizing data into objects, each identified by a unique key within a bucket, which serves as a container for storing the objects.
Data Hierarchy
FDAT incorporates the 3-tier hierarchical data model of the underlying InvenioRDM open-source repository software. This methodically divides data into three main levels.
Community Level: This primary level of the data hierarchy represents broader categories such as research groups or institutional units such as university faculties. Several metadata fields are available for the description of a community in the repository.
Collection Level: This level represents a collection of related data records within a specific community to group data files that belong to the same study or experiment, forming a cohesive unit.
Data File Level: The most granular level at which data is represented in individual files within a collection.
What data preservation measures are implemented in FDAT?
FDAT implements comprehensive data preservation measures and techniques to ensure that research data remains accessible, understandable, and usable over the long term. Below are the key data preservation strategies currently employed by FDAT:
Data Integrity & Authenticity
- Checksum Validation: FDAT uses checksum algorithms (MD5) to verify the integrity of data files. Checksums are generated at the time of data ingest and periodically verified to detect data corruption.
- Versioning: FDAT keeps track of actions performed on datasets, including creation, modification, and access through a comprehensive versioning mechanism.
Data Redundancy & Backup
- Secure Storage: The longevity and accessibility of the data in FDAT is ensured by utilizing the storage infrastructure bwSFS of the state of Baden-Württemberg, specialised in long-term scientific data storage.
- Multiple Copies: FDAT stores multiple copies of data in geographically dispersed locations within the bwSFS infrastructure to prevent data loss due to localized disasters or technical failures.
- Regular Backups: FDAT schedules regular automated backups of data and metadata to the secure, reliable storage infrastructure bwSFS.
Data Formats & Standards
- File Format Sustainability: FDAT evaluates the sustainability of file formats. When necessary, we recommend or facilitate migration to more sustainable or universally accepted formats.
- Standardization within disciplines: We provide researchers with advice on data formats and encourage to use discipline-specific data formats whenever possible. This promotes interoperability, allowing researchers from the same field to easily combine and analyze datasets.
Metadata & Documentation
- Descriptive Metadata standards: FDAT ensures data is accompanied by rich metadata using established standards like DataCite or CodeMeta. This descriptive information makes data discoverable and understandable for other researchers.
- Preservation Metadata: We advice and support researchers with the use of discipline-specific metadata schemas whenever possible.
Access & Use
- Persistent Identifiers: FDAT assigns persistent identifiers (DOIs) to datasets to ensure they can be reliably located and cited over time, regardless of changes in the repository’s infrastructure.
- Access Controls: FDAT implements robust Role-Based Access Control (RBAC) mechanisms and user based API keys to ensure that data is accessible only to authorized users while preserving the ability to make data publicly available when appropriate.
- Federated User Authentication: FDAT is connected to the federated user authentication service bwIDM as provided by the state of Baden-Württemberg to manage access to FDAT.
How long is data stored in FDAT, and how can it be removed?
FDAT guarantees that every published dataset will remain accessible for a minimum of ten full calendar years from its publication date. Long-term availability is essential for reproducibility and aligns with the good research practice recommendations of the Deutsche Forschungsgemeinschaft (DFG) as well as international FAIR data principles.
Why ten years?
Experience shows that most replication studies, re-analyses, and derivative publications occur within a decade of the original release. The ten-year window therefore secures the critical phase of scholarly reuse while balancing sustainability and cost.
Re-evaluation after the retention period
During the final year of retention FDAT undertakes a structured re-evaluation together with the data depositors based on:
- Disciplinary relevance and citation
- Legal or contractual obligations
- File-format sustainability and technical viability
- Storage cost
Possible outcomes of this review:
- Continued preservation (default if the dataset is still valuable or frequently accessed)
- Migration to a successor infrastructure
- Removal with a public withdrawal notice if the dataset is demonstrably obsolete and lacks residual scholarly value
Depositors will be contacted via their last known institutional e-mail address and may provide additional arguments for continued retention.
Early removal in exceptional cases
As FDAT is responsible for maintaining the scholarly record, early withdrawal or deletion is only possible if a justified request is submitted in writing and approved. Valid reasons for withdrawal or deletion include:
- Proven rights infringement or other legal violations
- Confirmed data-protection breach (e.g. GDPR)
- Retraction or fraud verified by a journal or institution
- Court injunction or statutory requirement
To streamline such requests, please use our standard form:
How to search for data in FDAT?
Search Recommendations
Simple Search: As an initial step, utilize the search bar on the main page, https://fdat.uni-tuebingen.de. You can optimise search results and save time by entering specific keywords or phrases relevant to the data you are looking for.
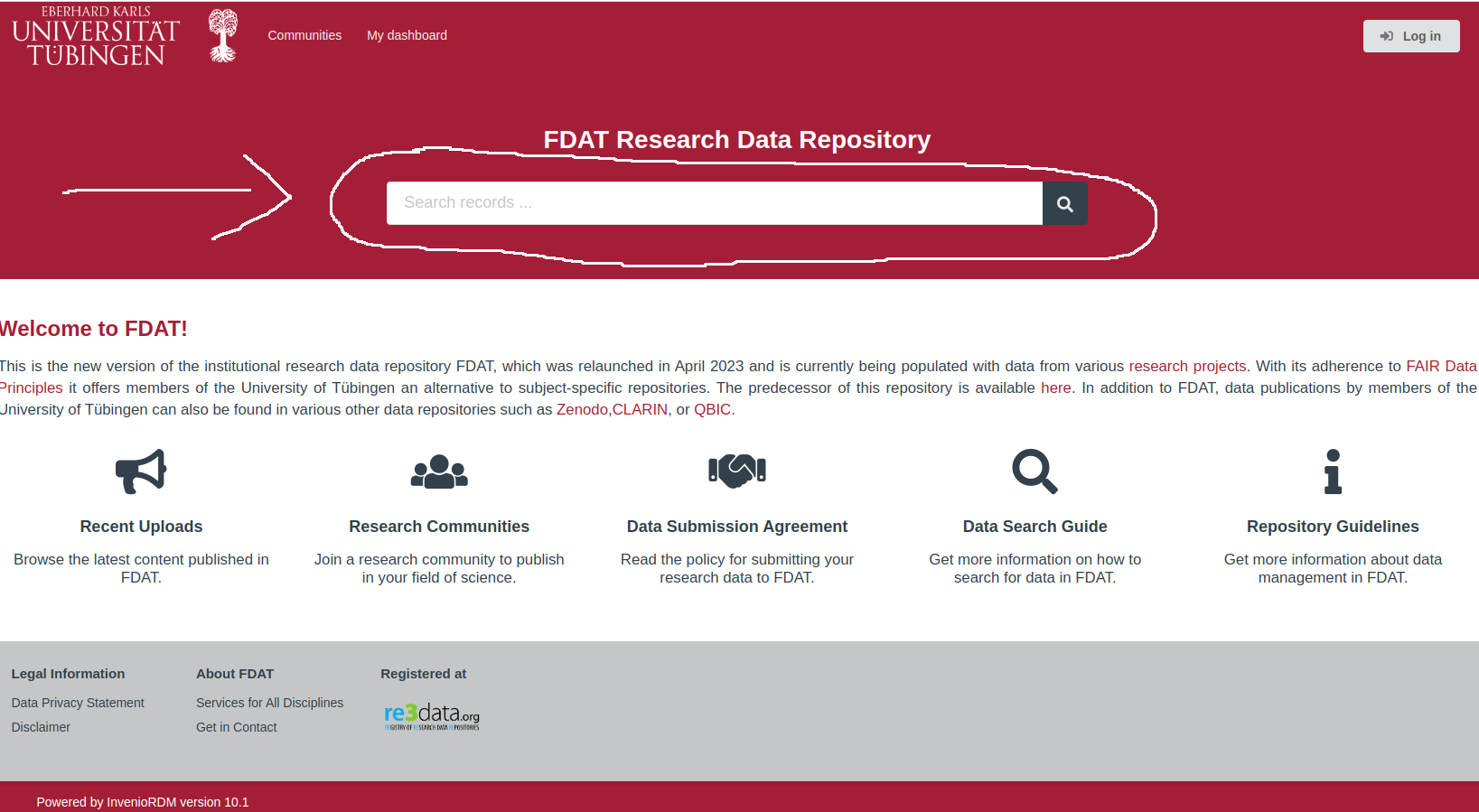
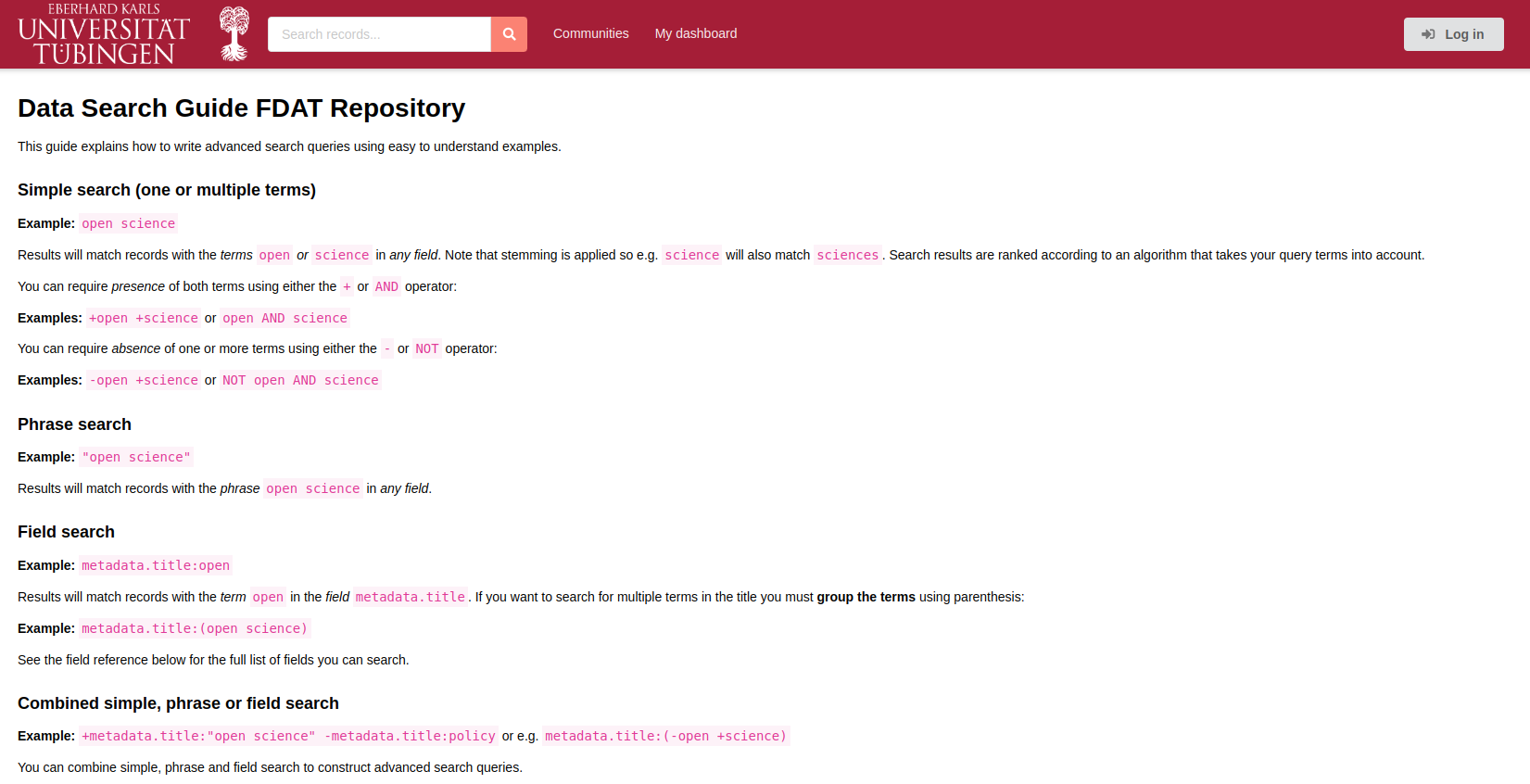
Advanced Search: A comprehensive data search guide is available on the web portal (see Fig.11 below) for those wishing to conduct a more nuanced search. This can be used to refine the process of locating and accessing specific research data within the repository.
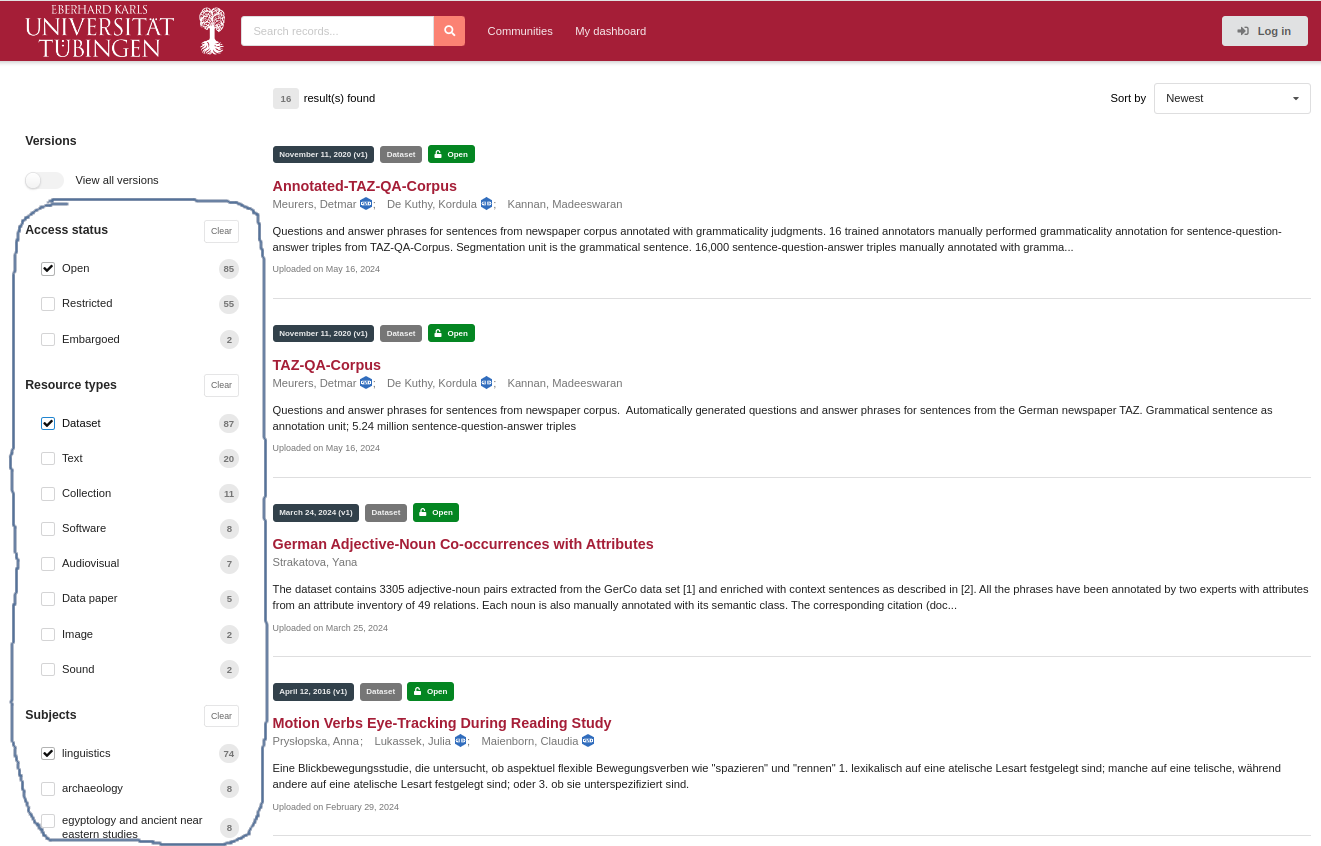
Faceted Search: FDAT integrates search facets within the left sidebar (see Fig. 12 below) of the search results page. Facets allow users to filter search results based on specific criteria such as data type or data availability.
How to access and download data and metadata in FDAT?
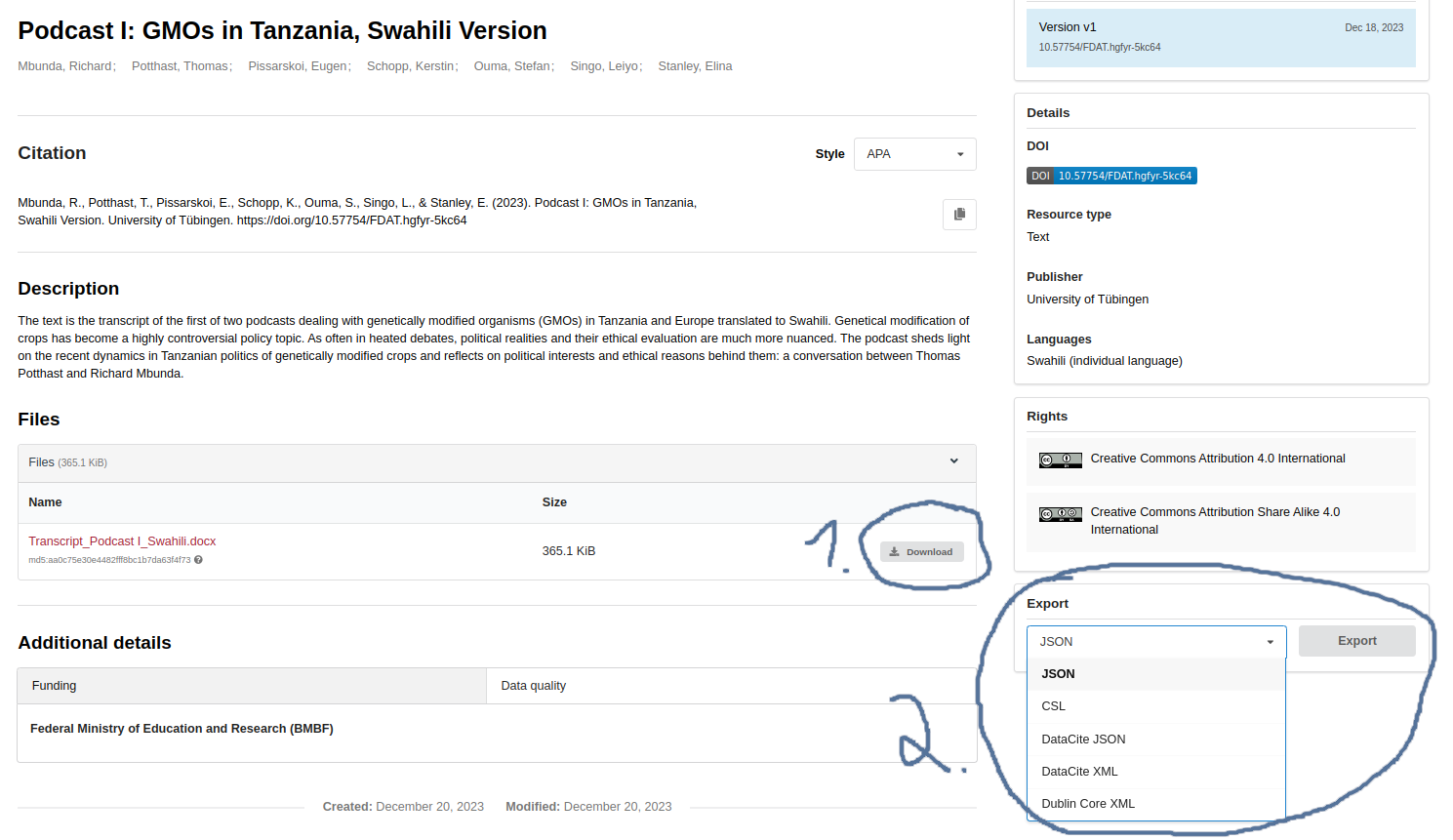
Web Portal: FDAT provides an intuitive web-based user interface, accessible at https://fdat.uni-tuebingen.de, that allows users to access and download data files and associated metadata, as illustrated in Fig. 13 below.
In order to access a specific data file of a data collection directly, use the following syntax in the browser: https://fdat.uni-tuebingen.de/records/{record_id}/preview/{file_name}. A working example is given for a PDF file like this: https://fdat.uni-tuebingen.de/records/08h77-abm28/preview/Manual_TInCAP_1_0.pdf
OAI-PMH Interface: FDAT supports the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH), allowing external systems to harvest metadata from the repository. This facilitates widespread dissemination and accessibility of metadata. More information is given in the reference pages of the InvenioRDM platform for OAI-PMH.
The OAI-PMH URL of FDAT is https://fdat.uni-tuebingen.de/oai2d.
For example, to list the metadata of all records in FDAT in DataCite format, the URL would be:
https://fdat.uni-tuebingen.de/oai2d?verb=ListRecords&metadataPrefix=oai_datacite.
How to register as a user in FDAT?
Default Authentication
Prerequisites: In order to register as a user within FDAT, you need to have a valid account that is associated with a university in Baden-Württemberg or beyond.
BwIDM: FDAT employs the state service bwIDM for user authentication. A comprehensive list of member organizations connected to bwIDM is available for reference.
Registration Steps
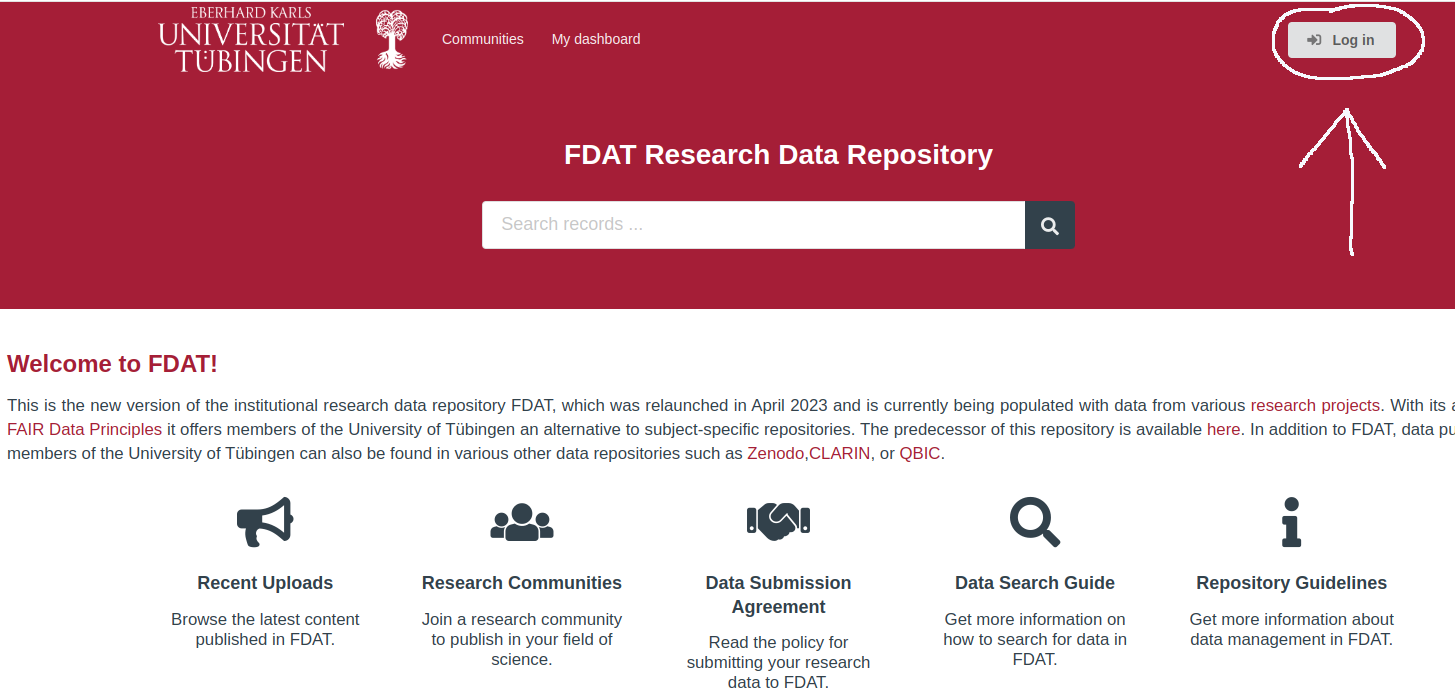
Step 1: Visit the FDAT landing page at fdat.uni-tuebingen.de and click on the 'Log In' button situated in the top right corner (see Fig. 14 below).
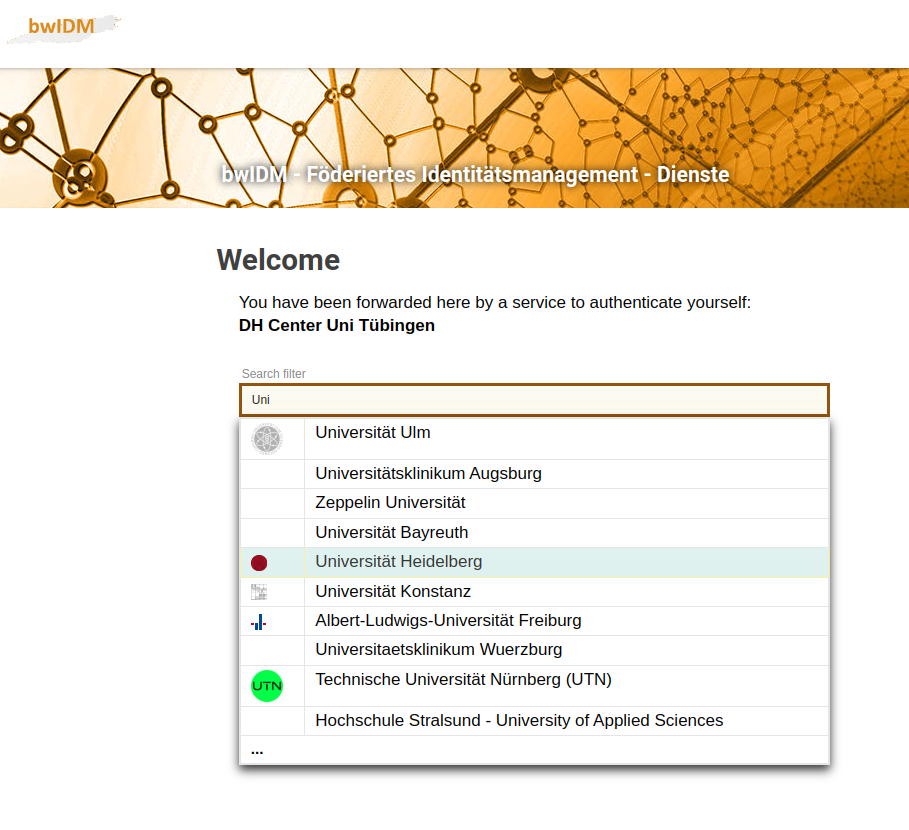
Step 2: You'll be forwarded to the bwIDM service site (see Fig. 15 below) where you select your affiliated institution, such as the University of Tübingen.
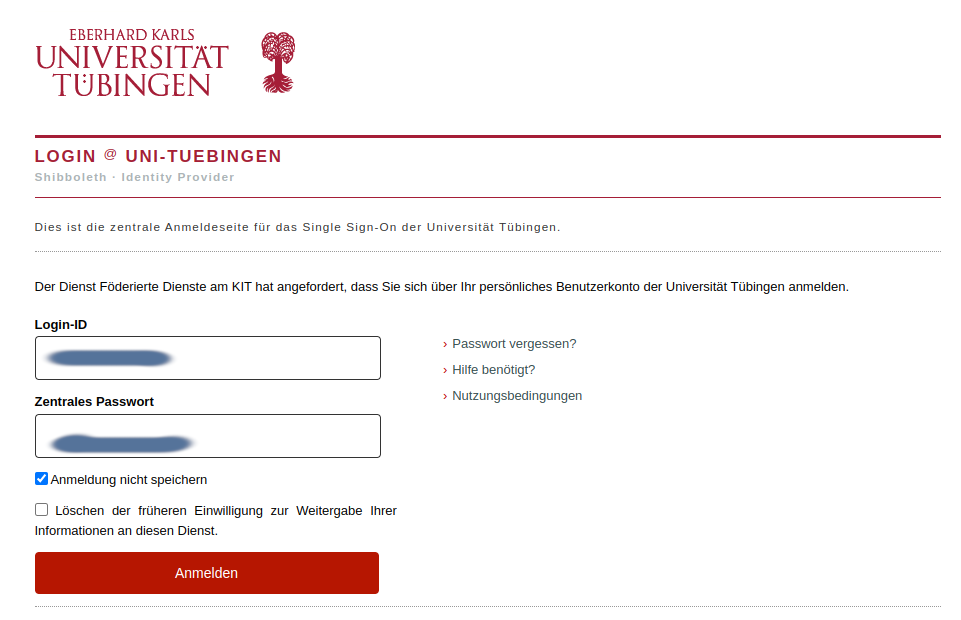
Step 3: bwIDM directs you to the IdP of your institution, were you have to provide your user credentials, as illustrated in Fig. 16.
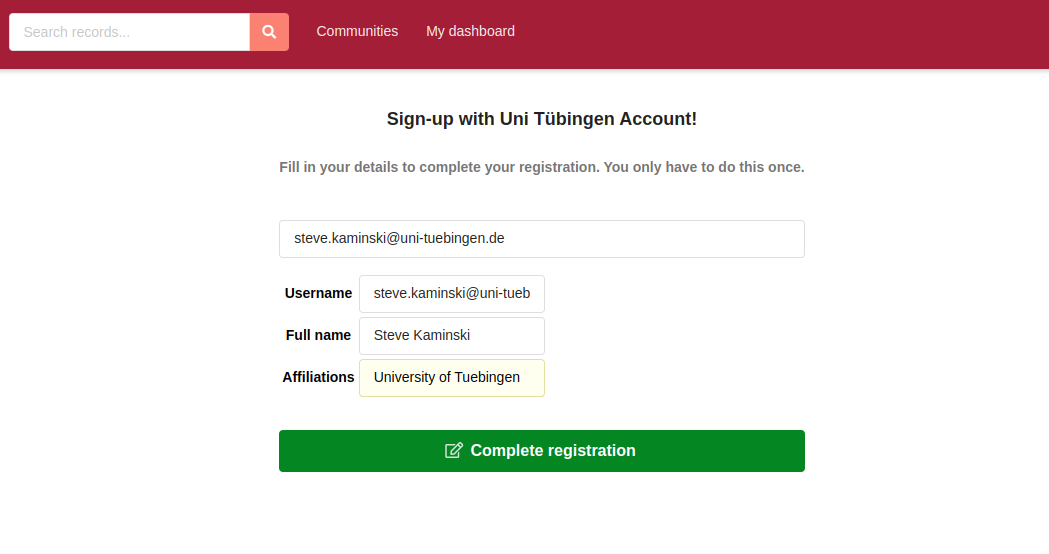
Step 4: You will be redirected back to FDAT (illustrated in Fig. 17). Continue to complete the registration process. It's important that you fill in all the mandatory fields correctly. In particular, the 'affiliation' field may require manual entry. For the username, it's best to use an identifier without special characters, ideally your institutional login ID.
Does FDAT restrict access to research data?
Data Classification by Access Rights
When searching for research data in FDAT, it is helpful to evaluate the accessibility status of data collections by using the 'Access status' facet in the left sidebar of the search menu, as shown in Fig. 18. Clicking on the 'Open' tab will filter the search results to show records where the contained files are available for download.
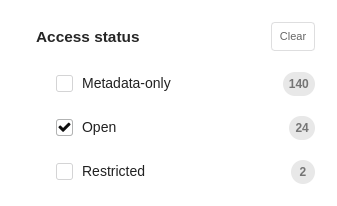
Open, Restricted and Embargoed Data
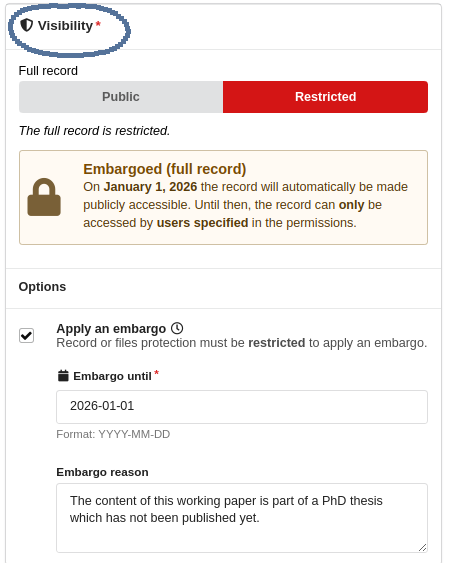
If records are marked as 'Open' by a green badge above the record title, as illustrated in Fig. 19, you can access and download the content without restriction. However, if data sets are labeled as 'Restricted', you need to receive permission from the data provider before downloading the data.
Moreover, data sets in the repository can be restricted for a certain time span (Embargoed). This means that the data is not publicly available for a certain period of time after it is deposited in the repository. In FDAT, there will be a reason given for the embargo of a specific dataset as well as an end date for the embargo.
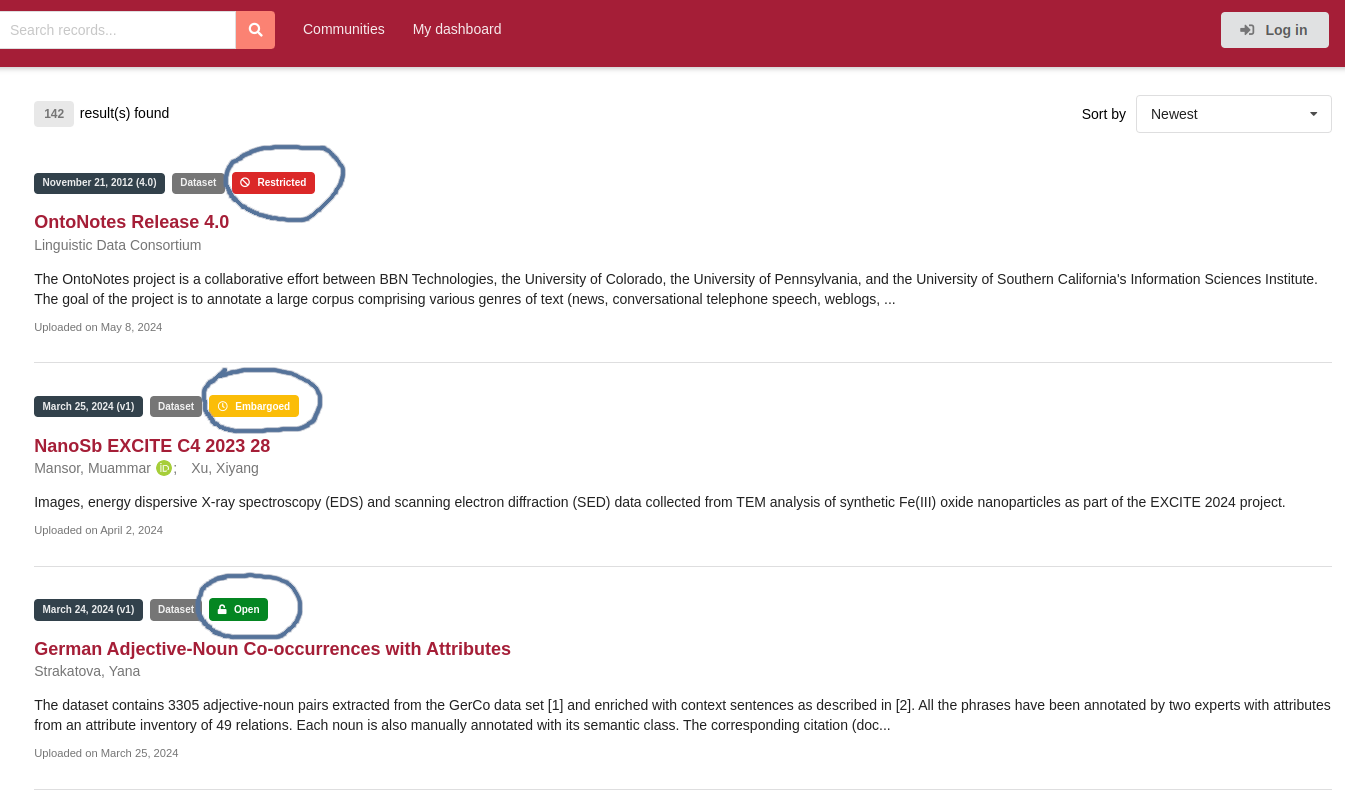
Embargoed Data
The purpose of an embargo period is to allow researchers to protect their data while they work on a publication or carry out further analysis. During this time, only the researcher and authorised individuals or organisations can access the data. At the end of the embargo period, the data becomes publicly available for others to access and use. The length of the embargo can vary depending on the researcher's preferences. Typically, embargo periods can range from a few months to a few years, depending on the nature of the data and the research project.

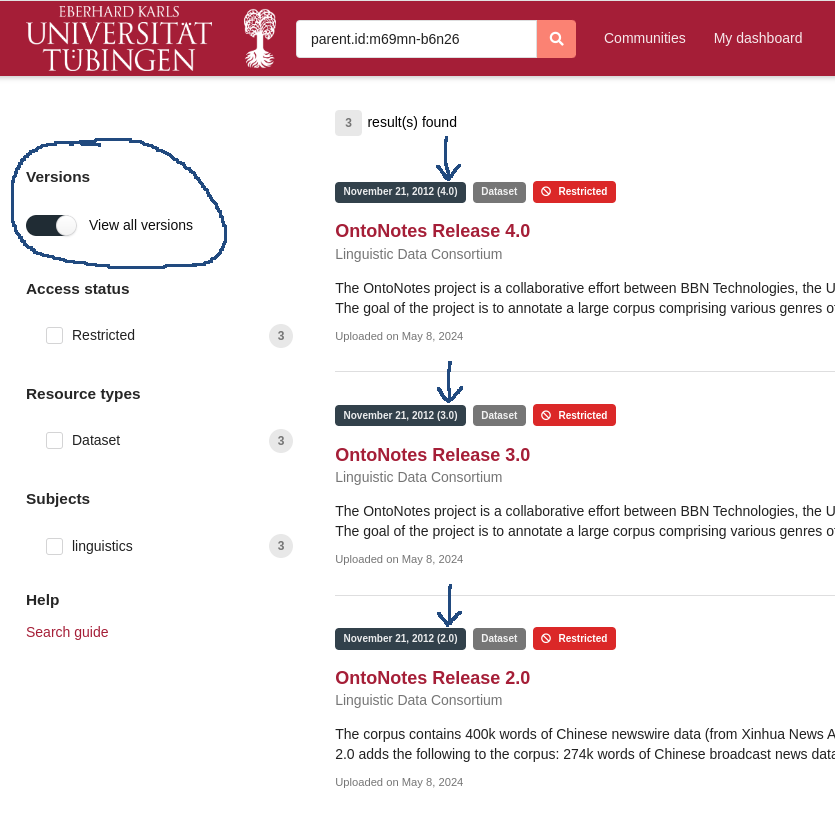
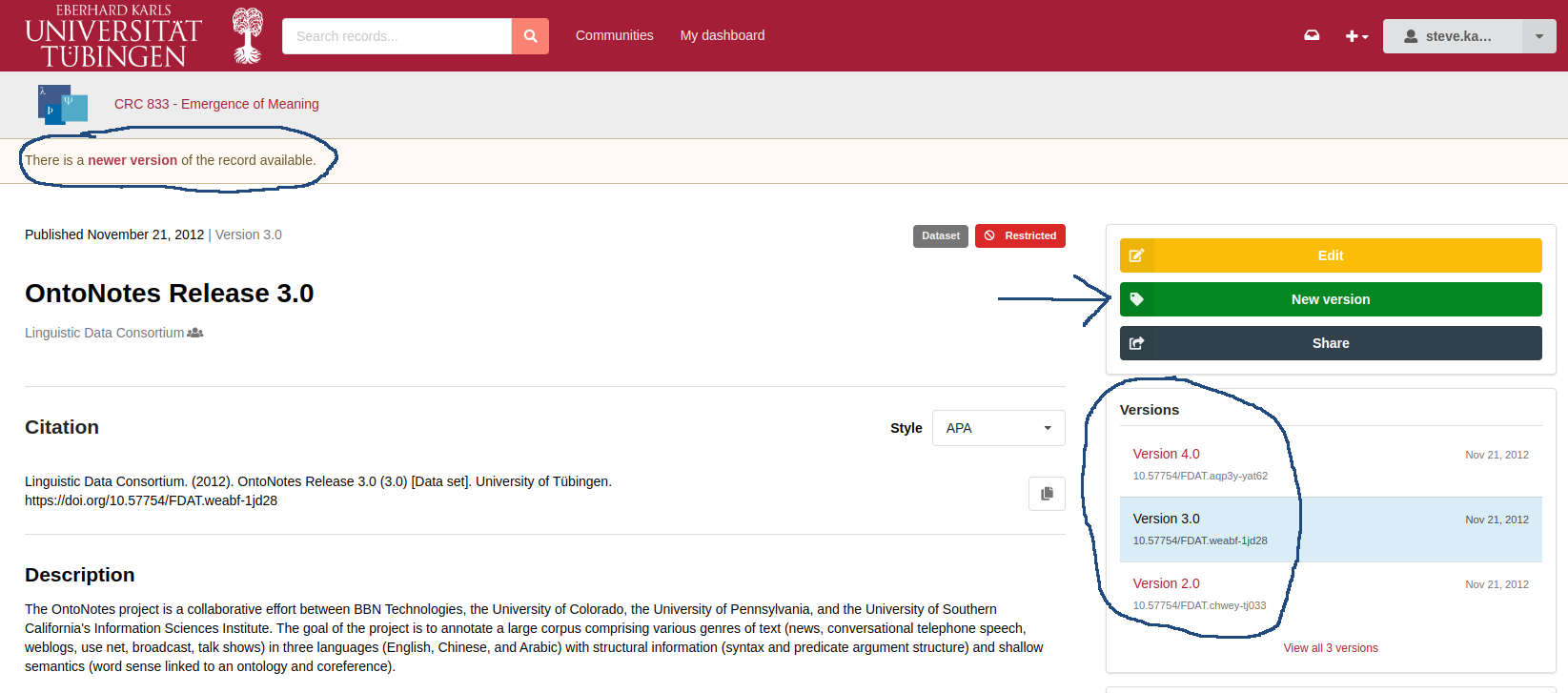
How does FDAT control and display data versioning?
In FDAT, dataset modifications are tracked to maintain a clear version history. A version of a record represents a specific state or snapshot of the dataset at a given point in time. Each version is immutable once published. Versioning is a critical feature for ensuring data integrity, reproducibility, and traceability in research. FDAT provides robust support for versioning research datasets. Here is a detailed explanation of how versioning is implemented in FDAT:
Creating a New Dataset:
- When a new dataset is created, it is assigned a DOI.
- This initial dataset is the first version (v1), per default.
Updating a Dataset:
- To update a dataset, a new version can be created by the owner of the dataset. This process involves duplicating the existing record's metadata and files, allowing modifications to be made.
- The new version is assigned a new DOI and retains a link to the previous version, maintaining a version chain.
- Changes can include metadata updates, file additions, deletions, or modifications.
Publishing a Version:
- Once the modifications are complete, the new version can be published.
- Publishing makes the version immutable and assigns it a new version number.
Version Navigation and Retrieval:
- Users can navigate between different versions of a dataset using the FDAT web portal, as shown in Fig. 21 and Fig. 22.
- Each version has its metadata, files, and DOI, allowing for unambiguous citation and retrieval.
- The system ensures that users can access previous versions to verify data consistency and reproducibility of research.
How to organize a new research project in FDAT?
Organizing a new research project in FDAT involves creating a structured environment for managing and sharing research data. This includes setting up a dedicated community, establishing a community policy, assigning responsibilities for data curation, and determining the metadata schema and reuse licenses. Below are the detailed steps to guide you through this process.
1. Creating a Community
The first step in organizing a new research project in FDAT is to create an Inveniordm community. This community will serve as the central hub for all data generated within the project. To create a community:
- Login to FDAT: Access the FDAT platform and log in with your credentials.
- Create a New Community: Get in contact with the Digital Humanities Center to get a research community created for your project.
- Define the Community Scope: Clearly outline the scope of the community and fill in the required details, such as the community name, description, and project affiliation. Specify the types of research data it will encompass and the intended audience.
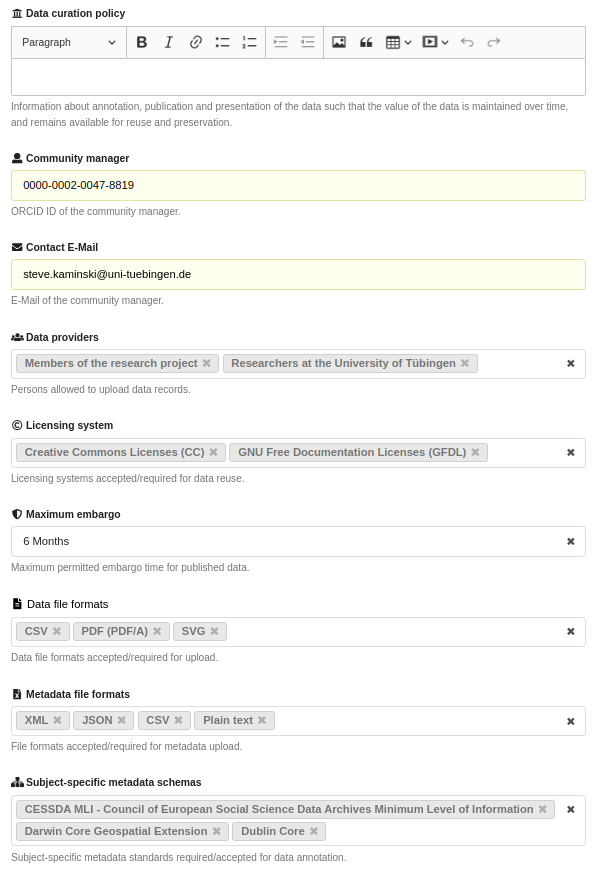
2. Establishing a Community Policy
The research community policy template covers essential aspects such as defining the scope of your community, identifying eligible data providers, setting data curation responsibilities, and determining conditions for data submission. By using this template, you can ensure that your community adheres to best practices in research data management, facilitating collaboration and enhancing the discoverability and reuse of your data.
We encourage all researchers to utilize this template to create a robust and effective policy for their research communities. Should you have any questions or require further assistance, please do not hesitate to contact our support team.
Click the link below to download the research community policy template.
3. Establishing Responsibilities for Data Curation
Assigning responsibilities for data curation is crucial for maintaining the quality and integrity of the data within the community. The community members should:
- Select Data Curators: Identify and appoint individuals responsible for reviewing, curating, and approving datasets for publication.
- Define Curation Standards: Establish clear guidelines and standards for data curation, ensuring adherence to the FAIR principles.
- Facilitate Communication: Maintain open communication channels between data providers and curators to address any issues or queries during the curation process.
4. Determining Conditions for Data Submission to the Community
To ensure proper data submission and management within the community, the following conditions should be determined:
- Community Manager: Appoint a community manager who will oversee the overall operations of the community and ensure compliance with the established policies.
- Suitable Data Providers: Identify the researchers and data providers eligible to submit data to the community, ensuring they align with the community's scope and objectives.
- Licensing Systems: Select suitable licenses for the data to ensure proper reuse and redistribution. Commonly recommended licenses include Creative Commons (CC BY) or Open Data Commons (ODC).
- Maximum Embargo Times for Datasets: Establish the maximum duration for which datasets can be embargoed, ensuring a balance between data protection and accessibility. Typically, this could be set to a specific number of months or years.
- File Formats for Datasets: Specify the preferred file formats for dataset submissions to ensure compatibility and usability.
- Metadata File Formats for Dataset Description: Define the formats for metadata files, such as CSV, XML, and JSON, to ensure consistent and comprehensive dataset descriptions.
- Discipline-Specific Metadata Schema for Dataset Description: Select metadata schemas that are specific to the research discipline, enhancing the relevance and discoverability of the datasets. Examples include Darwin Core for biodiversity data or DDI for social science data.
By following these steps, you can effectively organize a new research project in FDAT, ensuring robust data management, curation, and sharing practices. This structured approach will facilitate collaboration, enhance data quality, and promote the reuse of valuable research data.
What kind of content can be uploaded to FDAT?
FDAT is designed to support a wide range of research data content in a variety of file formats. Technically, FDAT supports any type of data stored in either text (human-readable) or binary file format, although it is strongly recommended that non-proprietary file formats suitable for long-term preservation are used. A comprehensive list of open formats can be found here.
Binary File Formats
Images: Common image file formats such as JPEG, PNG, AVIF and SVG are supported, facilitating the storage of visual data and high-resolution graphics.
Audio and Video: InvenioRDM accommodates multimedia files including MP3, Opus, Matroska and FLAC, allowing researchers to store and share audiovisual content.
Compressed Archives: Formats such as ZIP, B1 and TAR are supported, enabling the efficient storage and transfer of large datasets and collections of files.
Executable Files: Binary executable files like EXE, BIN and CSH are supported, useful for sharing software applications and tools used in research.
Text-Based File Formats
Plain Text: Simple text files with extensions such as TXT, CSV and Markdown are supported, allowing for the straightforward storage of tabular data, notes, and logs.
Markup Languages: Files using markup languages, including HTML, XML, and JSON, can be uploaded, facilitating the storage of structured data and metadata.
Documentation and Manuscripts: Formats such as PDF, HTML, OpenDocument and LaTeX are supported, enabling the storage and dissemination of research papers, documentation, and manuscripts.
Specialized and Other File Formats
Scientific Data Formats: Domain-specific data formats such as FITS (Flexible Image Transport System for astronomy), HDF5 (Hierarchical Data Format for scientific data), and NetCDF (Network Common Data Form for geoscience data) are supported to meet specialised research needs.
Spreadsheet Files: Formats including CSV and OpenDocument Spreadsheet (.ods) are supported, allowing researchers to store and share complex data tables.
Presentation Files: Presentation formats such as OpenDocument Presentation (.odp) can be uploaded, enabling the storage of research presentations and lecture materials.
Geospatial Data Formats: Geospatial file formats like Shapefile (.shp), GeoJSON, and KML are supported, allowing the storage and sharing of geographic data and spatial analyses.
Metadata and Descriptive Formats
Metadata Files: Files containing metadata descriptions in formats such as JSON and XML can be uploaded, to provide comprehensive metadata for research datasets.
Descriptive Data: Text-based descriptive files, including README files and data dictionaries, are supported, helping to document and describe the content and structure of datasets.
How to prepare data before uploading to FDAT?
Selection of Research Data: As a researcher, it is imperative that you assess the archival value and scientific relevance of the data you are considering contributing to a research data repository. The selection process should be guided by specific criteria to ensure that only data of significant scientific value and potential for future reuse are archived. Detailed guidelines for the selection and evaluation of research data are essential resources to consult.
Structuring and Naming of Files and Folders: In the FDAT repository, data can be stored and organized in a 3-tier hierarchical structure as described in the section 'How is data structured in FDAT?'. This structure enhances the usability and accessibility of the data. Researchers should take advantage of theses features by systematically structuring their data accordingly.
Recommendations for Structuring:
- Data Hierarchy and Granularity: Data should be organized into a hierarchical structure with clear levels of granularity. For example, top-level folders could represent broad project categories, with subfolders detailing specific experiments, datasets, or time periods.
- Documentation: Include comprehensive documentation within each folder to describe its contents and the methodology used to generate the data. This can include README files, metadata files, and data dictionaries.
Systematic Naming Conventions:
- Descriptive Names: Use clear and descriptive names for files and folders that reflect their content without being excessively lengthy. Avoid the use of incomprehensible abbreviations and special characters that can complicate file handling.
- Standardized Format: Adopt a standardized naming format that includes key information such as the project name, date of creation, version number, and a brief description. For example, `ProjectName_YYYYMMDD_Version_Description`.
Metadata and Documentation:
- Research-specific Metadata Schema: Researchers should find and use research-specific metadata schemas to annotate their data. These schemas, which are tailored to specific disciplines, should be provided as additional files alongside the data files.
- README Files: Each dataset or folder should contain a README file that provides an overview of the data, instructions for use, and contact information for the data creator. This helps other researchers understand and utilize the data effectively.
What is the process for uploading and annotating data in FDAT?
Researchers can either select an existing community or initiate a new one related to a research project to deposit their data. For the latter option, it is mandatory to get in contact with the Digital Humanities Center for guideance through the process.

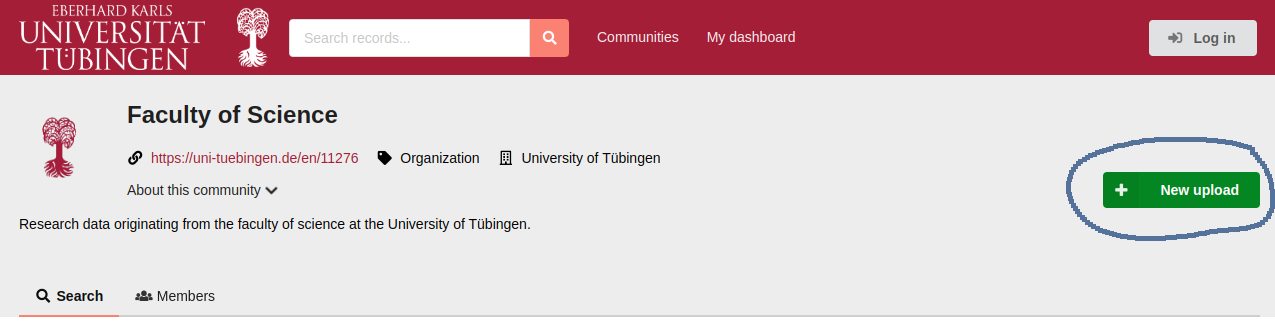
2. Upload Data Collections for a Community
Collections in FDAT are thematic clusters of data within communities. Each collection typically revolves around a specific research topic or set of experiments. To begin the process of uploading data, click on the 'New Upload' button, as shown in Fig. 25 below.
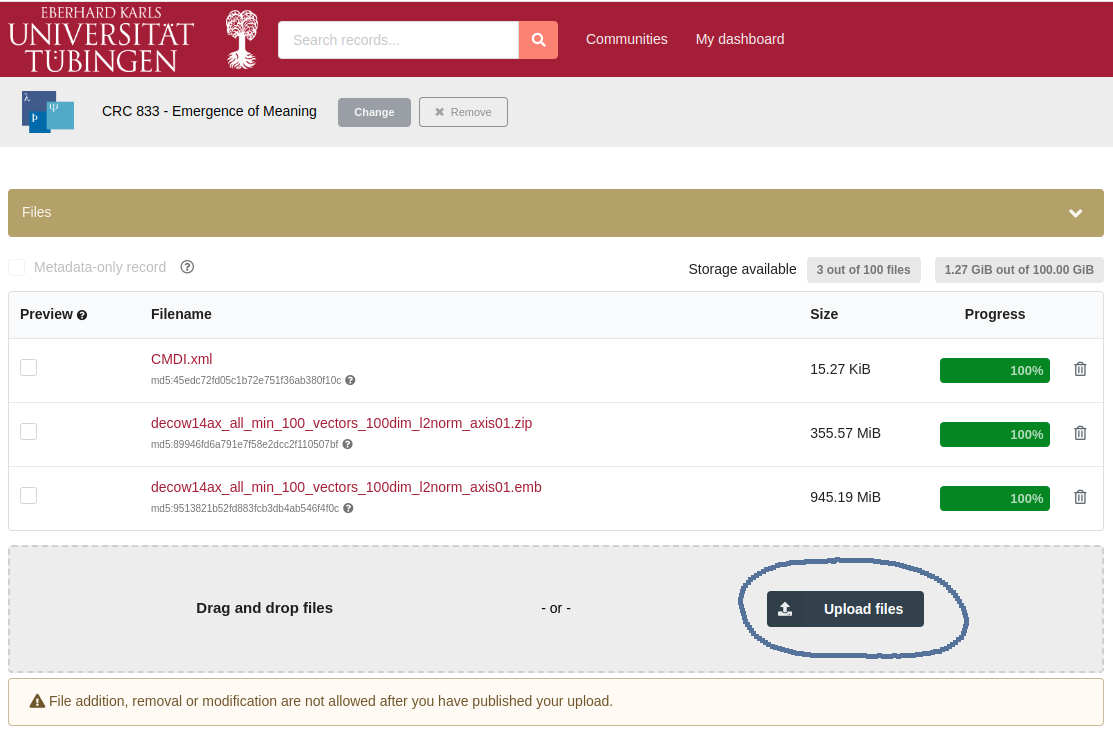
3. Upload Data Files for a Collection
Once a collection has been created, the next step is to upload data files to that collection, to be found under the 'Files' section.
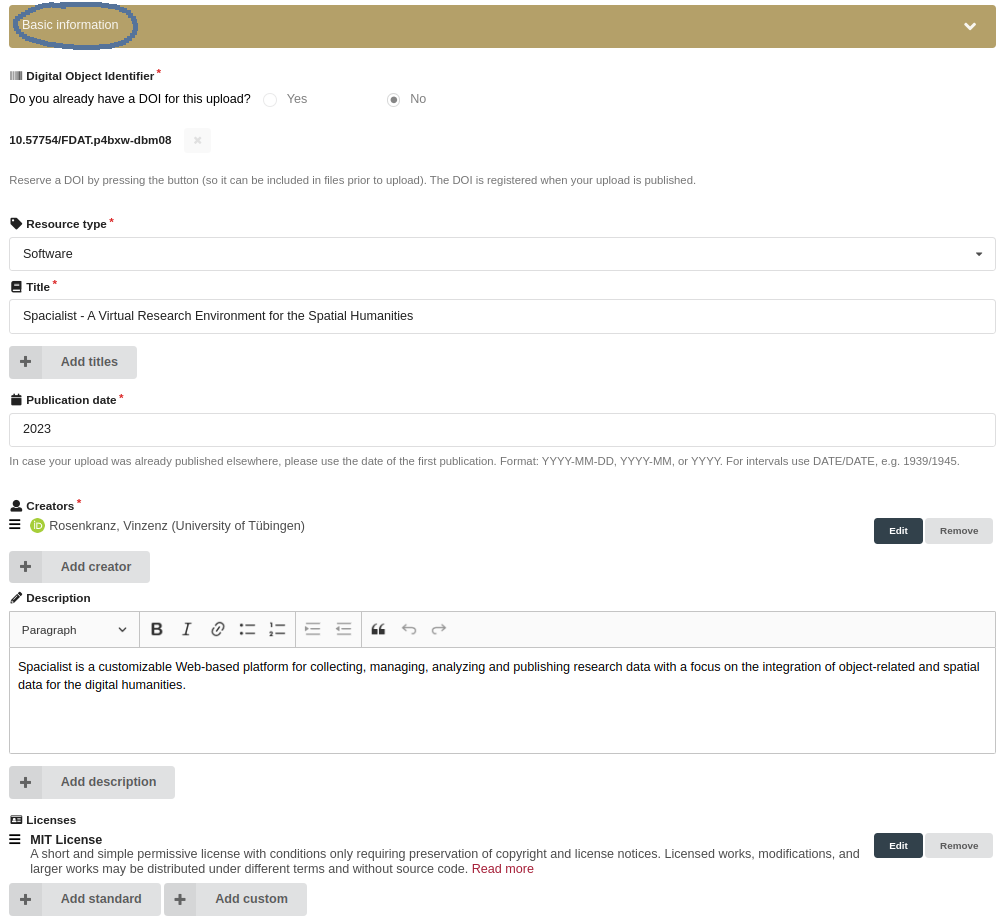
4. Provide Metadata for a Collection
After all the data files have been uploaded to a collection, the next step is to provide metadata under the 'basic information' section, as illustrated in Fig. 27.
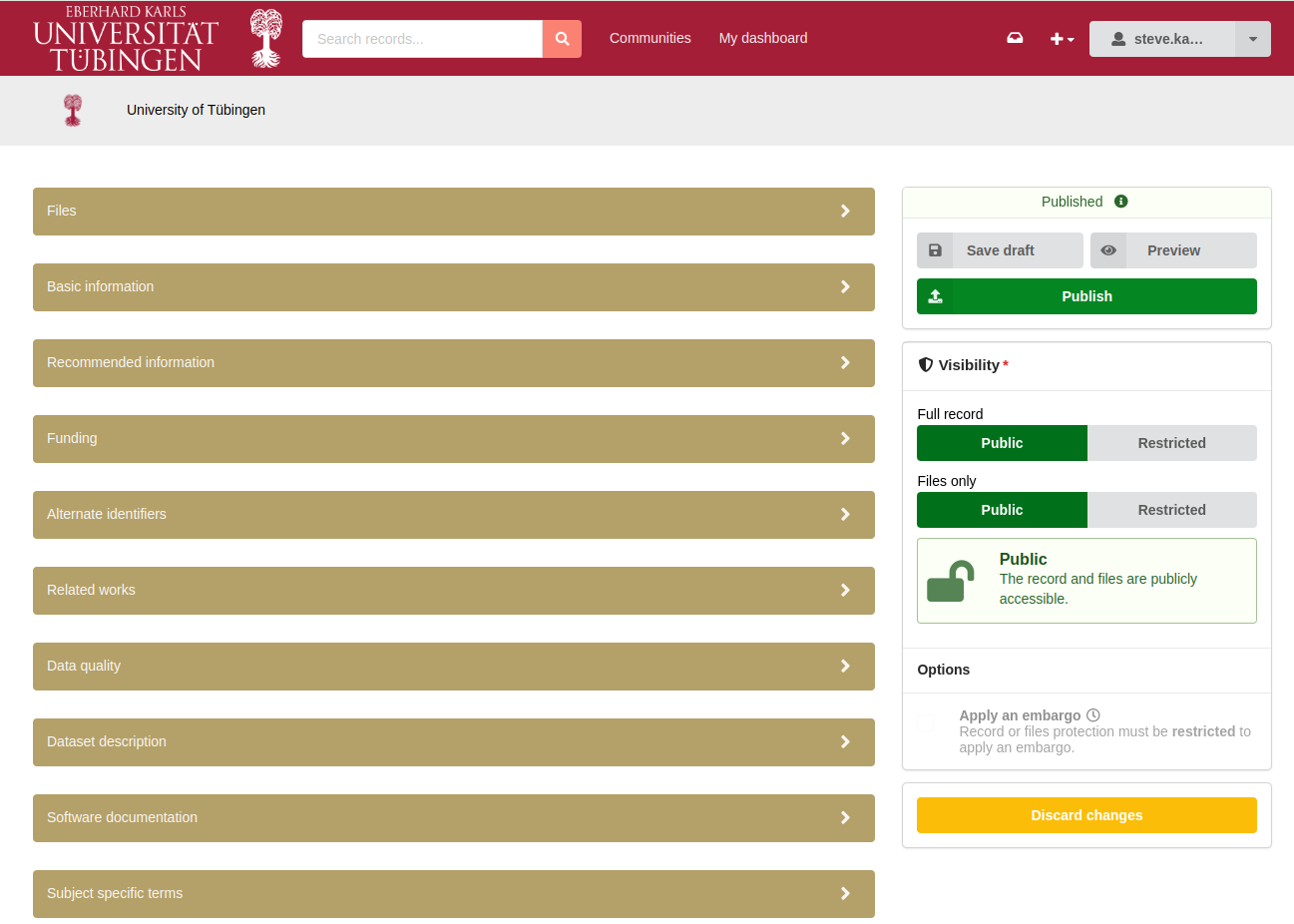
5. Set Data Visibility for a Collection
After metadata annotation, the visibility/accessibility of the data collection needs to be determined. The visibility of the data files can be set separately from the visibility of the metadata.
Is there a data upload limit for FDAT?
In general, there are limits to the amount of data that can be uploaded to FDAT due to the limitations of the underlying storage hardware. However, the University of Tübingen, together with the state service bwSFS, is committed to providing the necessary amount of storage for all research data worth archiving and publishing.
There are also specific restrictions on uploading data at the data collection level. These are as follows.
Data Collection Size: Each data collection in FDAT has a maximum storage limit of 500 gigabytes. This means that the total size of all files within a single collection must not exceed this limit.
Number of Files: Up to 100 individual files can be uploaded within each data collection. This allows for diverse data sets, but ensures manageability and efficient data retrieval.
A Note on Handling Large Datasets
How is data enriched with metadata in FDAT?
By integrating the following schemas and protocols, FDAT ensures that stored research data is enriched with high-quality, interoperable metadata to facilitate its discovery, reuse, and long-term preservation. In FDAT, metadata is divided into 9 categories (see Fig. 29 below) from which only 'Basic information' and 'Data quality' are mandatory.
Metadata Schema for Research Data
The DataCite metadata schema is a standardized framework for describing research data, ensuring consistent, comprehensive and interoperable metadata across various repositories and platforms. It includes a set of core elements, all be found in the 'Basic information' section (see Fig. 30 below) in the metadata web interface, designed to capture essential information you need to provide to receive a Digital Object Identifier for your dataset.
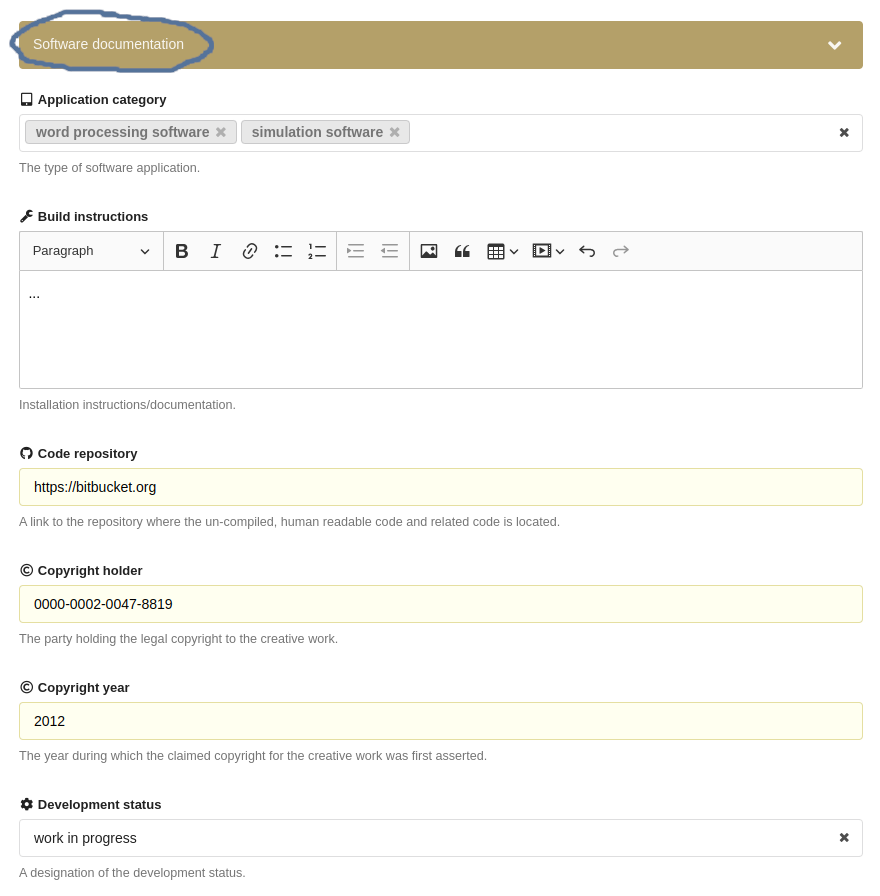
Metadata Schema for Research Software
The CodeMeta metadata schema is a standardized framework specifically designed for describing software and its related artifacts. It extends the Schema.org vocabulary to better capture the nuances of software metadata, facilitating the integration and exchange of information about software across different platforms and repositories. In FDAT, we have included a respective web interface for capturing software metadata under the 'software documentation' tab, as illustrated in Fig. 31 below.
Data Quality Description
FDAT requires the description of data quality for every uploaded dataset in a free text format (see Fig. 32 below), following the terminology (accuracy, completeness, ...) of the EU on data quality as published under doi:10.2830/333095.
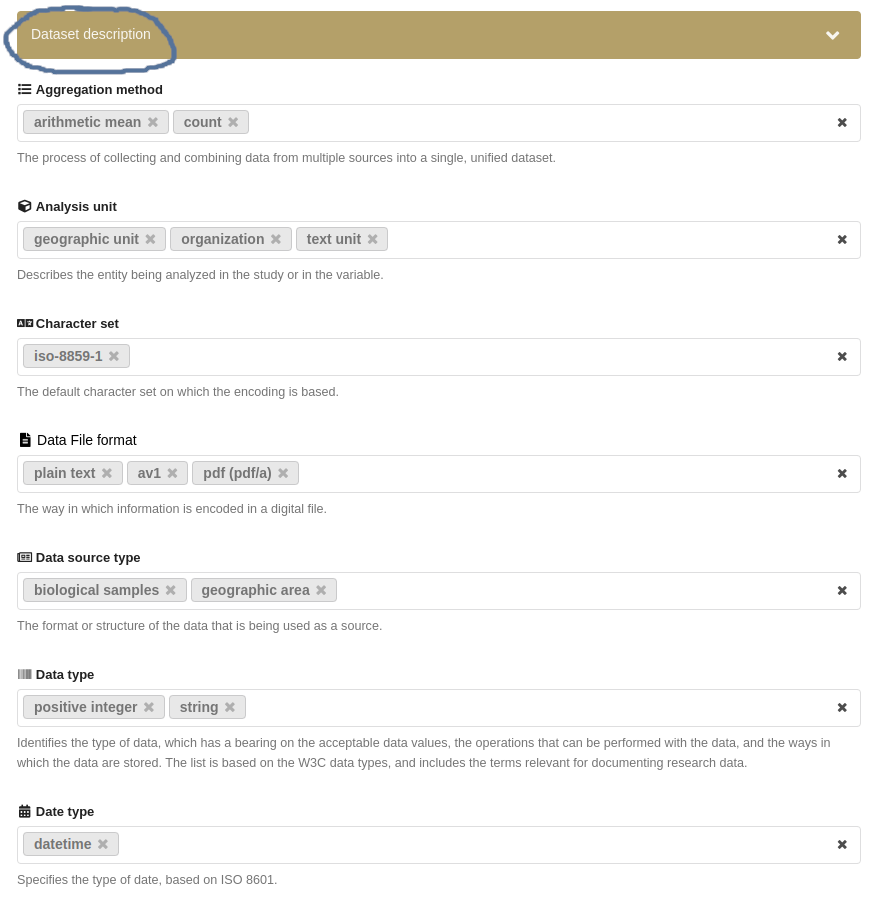
Controlled Vocabularies for Dataset Description
The Data Documentation Initiative (DDI) provides controlled vocabularies that are essential tools for standardizing terminology in research data description and metadata management. These vocabularies consist of predefined lists of terms that cover various aspects of data collection, processing, analysis, and dissemination. By using controlled vocabularies, researchers can ensure consistency and clarity in the documentation of their datasets, facilitating data sharing, interoperability, and reuse. Controlled vocabularies from the DDI encompass a wide range of categories, including survey methods, data types, geographic locations, and temporal coverage. They help in the precise categorization and tagging of research data in FDAT, making it easier for researchers to find, understand, and integrate datasets from different sources.
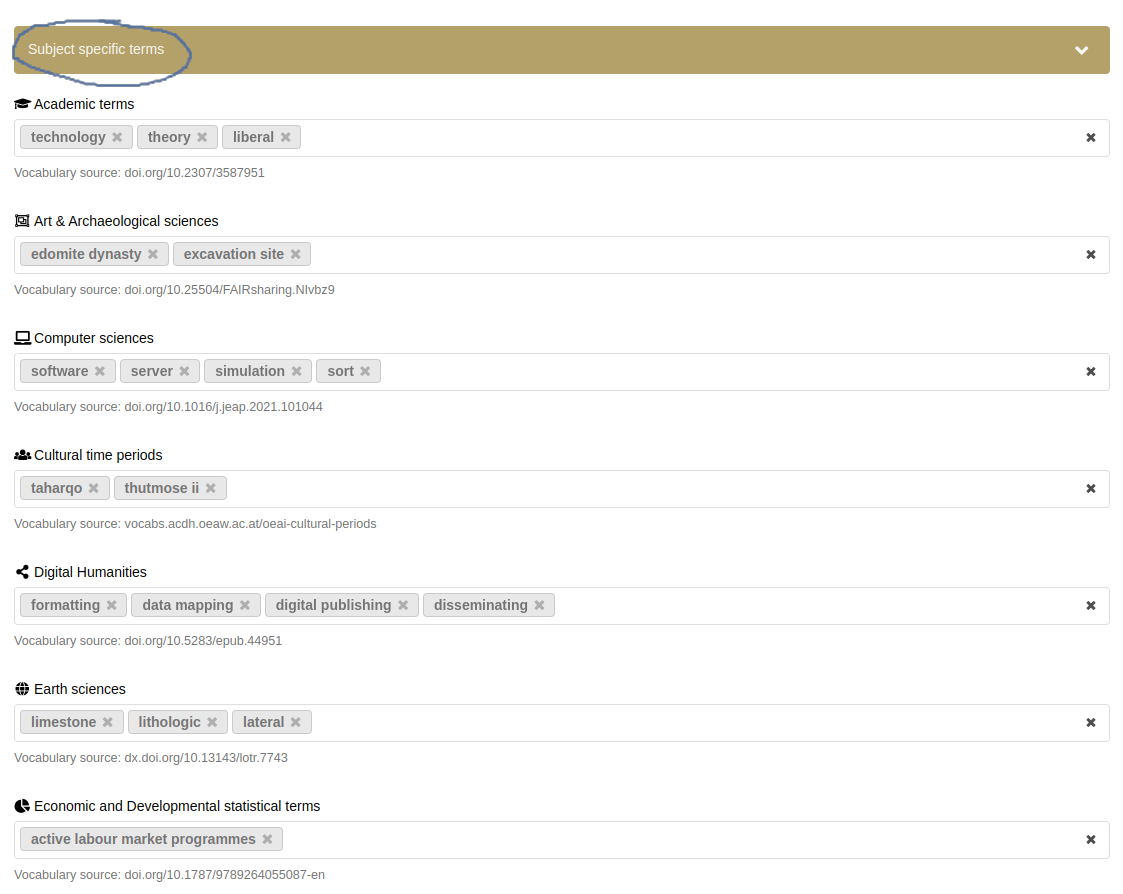
Controlled Vocabularies for Subject-Specific Keywords (Humanities & Social Sciences)
Dataset description in FDAT includes the allocation of subject-specific keywords from curated and published controlled vocabularies. Such vocabularies provide a standardized set of terms that ensure uniformity in the description of research data across different datasets and repositories. This standardization reduces ambiguity and enhances the precision of metadata. Currently, FDAT supports controlled keywords (see Fig. 34 below) from 20 disciplines from the humanities and social sciences which were mostly taken from fairsharing.org. Under each input field in the FDAT web interface, the persistent identifier of the published vocabulary can be found
What is the process of publishing data in FDAT?
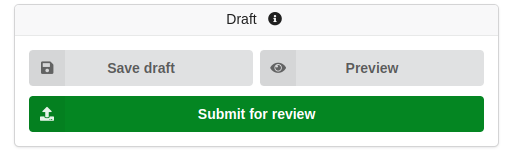
1. Submit a Data Collection for Review
To initiate the process of publishing data in FDAT, researchers must first submit their data collection for review. This involves logging into the FDAT platform and creating a new data record. Researchers should ensure that the metadata describing the dataset is thorough and accurate, including relevant information such as the title, authors, keywords, abstract, and funding sources. Files associated with the dataset should be uploaded in appropriate formats, and any necessary documentation, such as data dictionaries or methodology descriptions, should be included to facilitate understanding and reuse of the data.
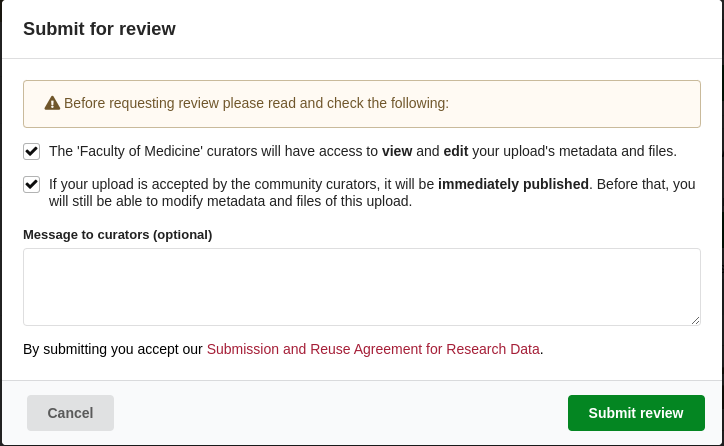
2. Consent with the respository data policy
Before the data collection can proceed to the review stage, researchers must consent to the institutional data policy outlined by FDAT. This policy ensures that data management practices adhere to ethical, legal, and institutional standards. Researchers are required to confirm that their data complies with these standards, including considerations for privacy, confidentiality, and intellectual property rights. Consent is typically given through an electronic agreement within the FDAT platform, and this step must be completed before the review process can advance.
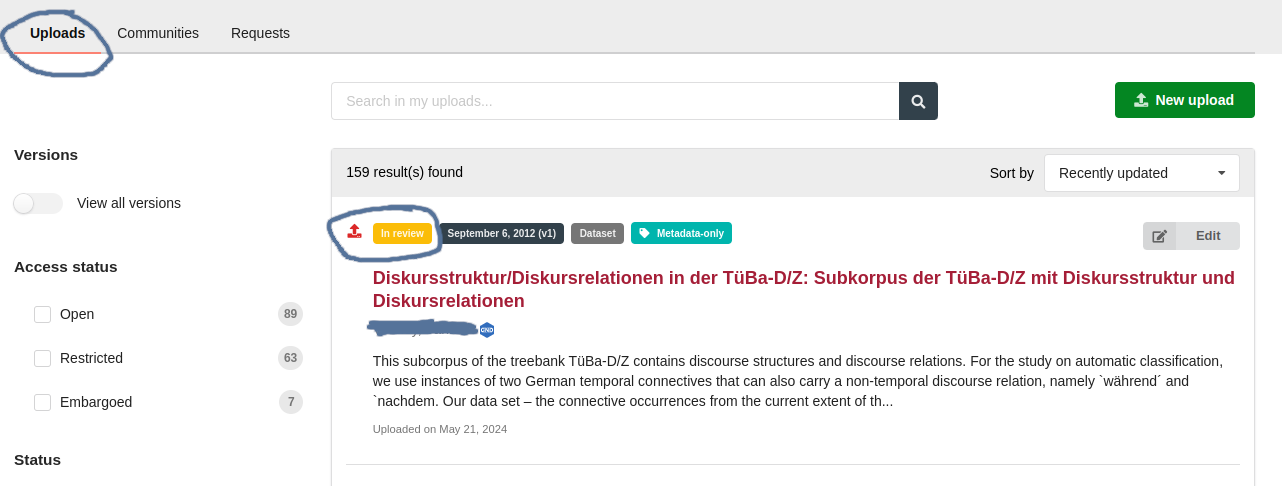
3. Awaiting the Data Curation Process
Once submitted, the dataset under review can be found in the 'uploads' section of the dataset owner's FDAT account (see Fig. 37 below) and is marked with a yellow badge that says 'under review' until the data curator has made a final decision on the dataset's publishability. During this phase, one or more data curators review the submission to ensure that it meets the repository’s quality and compliance standards. This includes verifying the accuracy and completeness of metadata, checking for any issues with the data files, and ensuring that the dataset adheres to the FAIR principles. The data curators may communicate with the researchers to request additional information or modifications if needed. The duration of this process can vary depending on the complexity of the dataset and the responsiveness of the researchers.
4. Data Published and Archived
Once the submitted dataset has undergone a successful review process, a green tick will be added to the dataset in the researcher's upload section (see Fig. 38 below). Now, the dataset is formally published and archived in the FDAT repository and is assigned a persistent identifier (DOI), which facilitates citation and long-term access. The dataset metadata will be indexed in the repository search engine to enhance its visibility and discoverability ensuring the data is preserved and can be effectively shared and reused by others in the future.
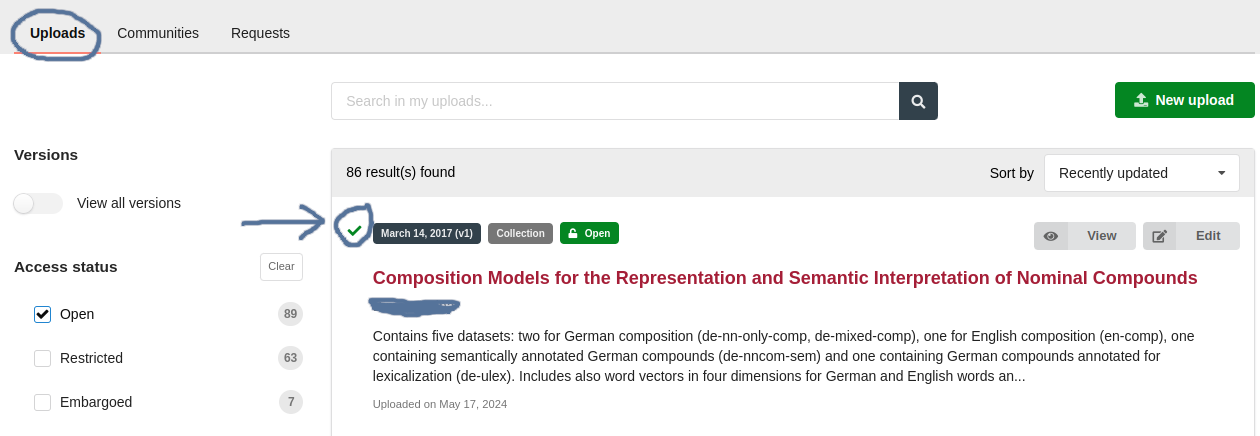
How is data made citable in FDAT?
FDAT incorporates the DOI (Digital Object Identifier) system to make research data permanently citable, recognising the widespread acceptance of DOI as a tool for identifying and citing research data
DOI Structure and Function
Unique Identifiers: Within the DOI system, datasets receive distinct identifiers, establishing a persistent link to the data. This facilitates accurate citations and seamless data retrieval.
Metadata Inclusion: The DOI system integrates essential metadata, such as authorship, titles, and publication dates. This ensures proper data attribution and optimizes discoverability.
DOI Acquisition Process
Metadata Submission: To obtain a DOI, researchers must provide relevant information about the dataset, including title, creators, identifier, publisher, publication year and resource type.
Early DOI Assignment: A unique DOI can already be reserved during the data preparation process (see Fig. 39 below).

DOI Source and Formatting
DataCite Affiliation: FDAT obtains DOIs from DataCite, a non-profit organization dedicated to enabling data citation.
Distinct DOI Prefix: FDAT provides its unique 10.57754 DOI prefix and embeds the FDAT acronym within each DOI suffix.
DOI Display: The landing page of each record published in FDAT highlights DOIs like badges.
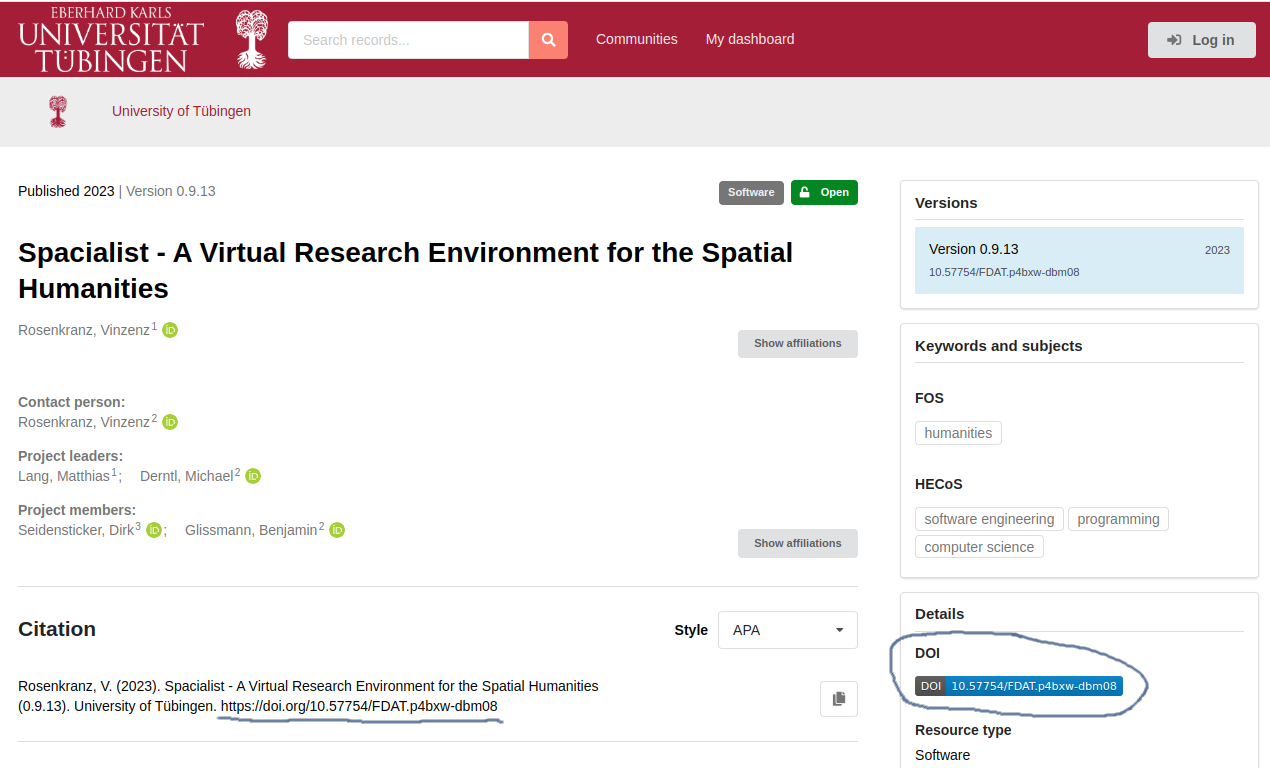
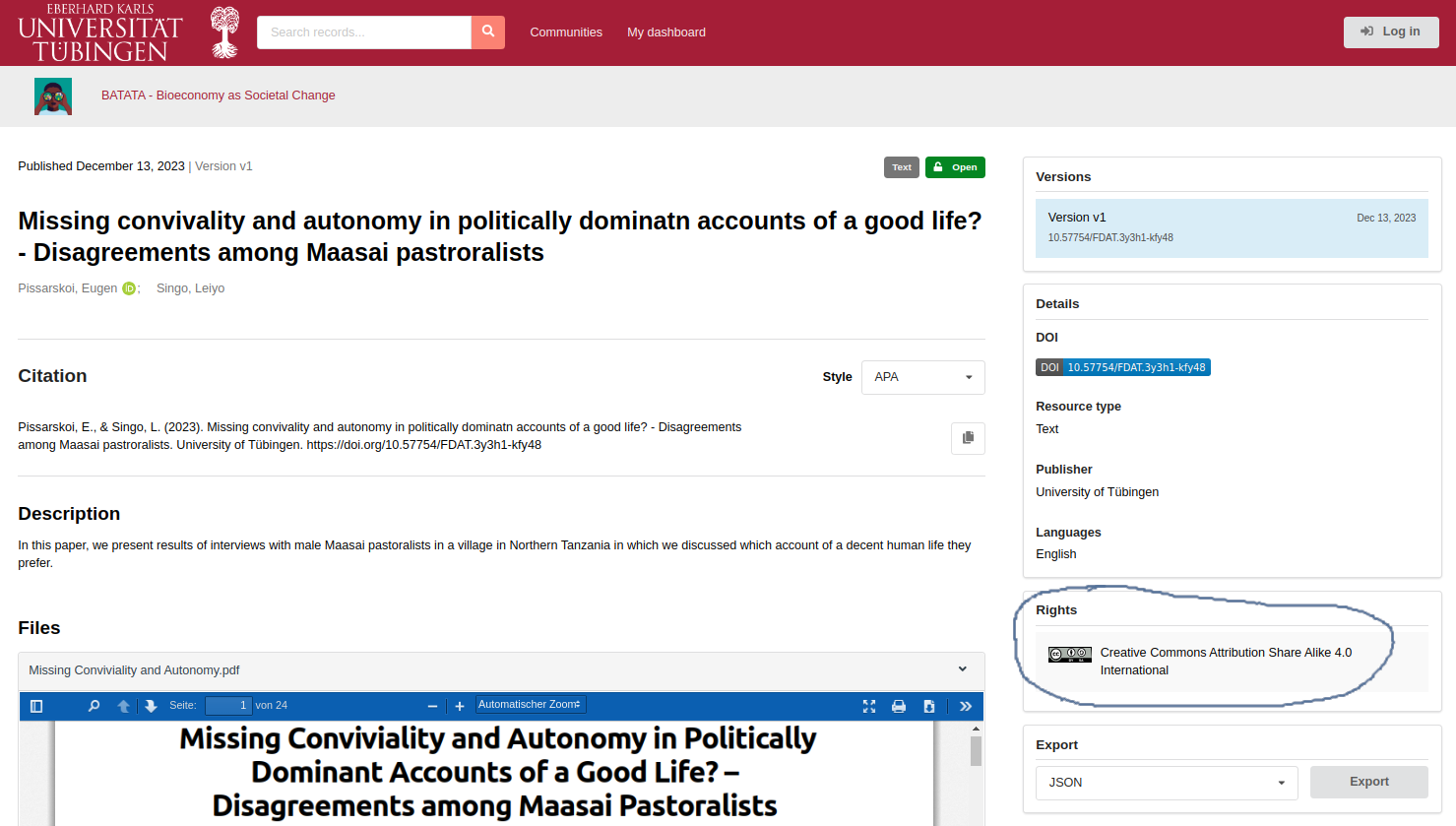
How is the data in FDAT licensed for reuse?
FDAT is committed to the University of Tübingen's Open Access policy policy and to the re-use of research data. Licensing is an important part of ensuring that users have a clear understanding of how they can use datasets published in FDAT. The following section outlines the licensing options and features available within the FDAT repository.
Predefined Licenses: FDAT comes with a set of pre-defined open content licences that streamline the process of licensing datasets. Some of the most commonly preferred licences include Creative Commons licences for research data and the MIT licence for research software. These licences facilitate open access, sharing and reuse of research results with minimal restrictions.
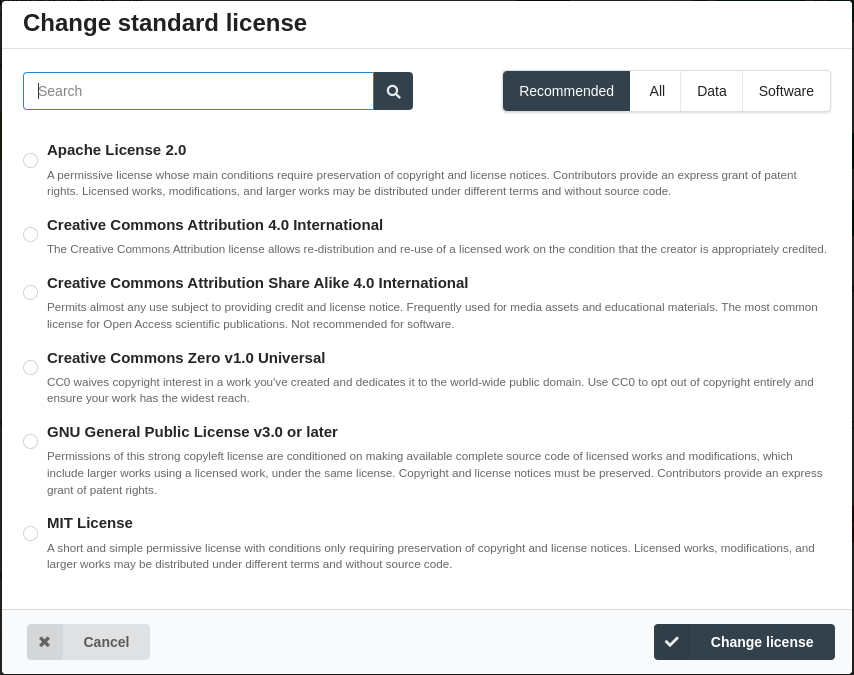
Custom Licenses: While the use of standard open content licences is encouraged, we recognise that some datasets may require unique licensing terms. Therefore, FDAT allows users to create and assign custom licences to their datasets, facilitating flexibility in data sharing conditions while ensuring compliance with specific requirements or conditions.
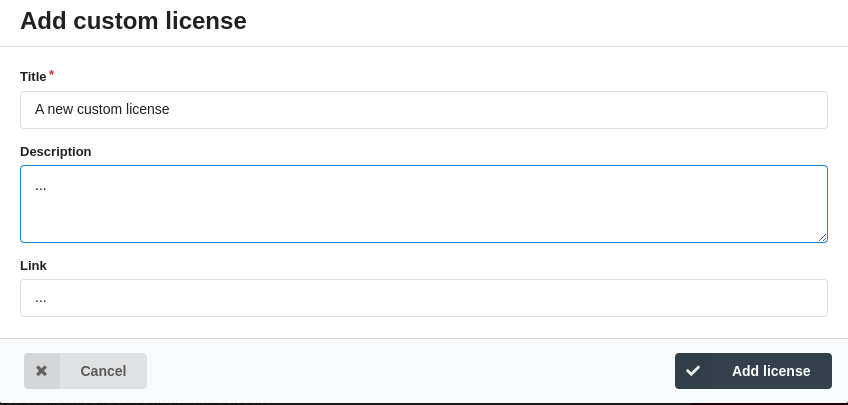
License Description: Each dataset in FDAT is accompanied by associated licensing information in the form of a textual description and a link to the original source of the licence, as shown in Fig. 43. This ensures that anyone accessing the data is immediately aware of the terms under which it has been made available.
License Visibility: Licensing information is clearly displayed for each dataset in the FDAT portal (see Fig. 44 below), ensuring transparency and clarity for potential users.
How can data from FDAT be systematically harvested?
The FDAT OAI-PMH endpoint enables external aggregators (e.g. OpenAIRE, BASE, re3data) to harvest publicly visible metadata for all datasets and research-software objects curated in FDAT. The interface complies with OAI-PMH v2.0 and follows the specialised DataCite OAI profile.
Protocol Specification
Base URL:
https://fdat.uni-tuebingen.de/oai2d
- Transport: HTTP GET (required) and HTTP POST (optional).
- Encoding: UTF-8 XML; responses validate against the OAI-PMH XSDs.
- Verbs implemented:
Identify,ListMetadataFormats,ListSets,GetRecord,ListIdentifiers,ListRecords.
Quick-Start Examples
- Basic repository information:
https://fdat.uni-tuebingen.de/oai2d?verb=Identify - List of metadata formats:
https://fdat.uni-tuebingen.de/oai2d?verb=ListMetadataFormats - List sets (Communities in FDAT):
https://fdat.uni-tuebingen.de/oai2d?verb=ListSets - List all identifiers (DataCite format):
https://fdat.uni-tuebingen.de/oai2d?verb=ListIdentifiers&metadataPrefix=oai_datacite - List all records (Dublin Core format):
https://fdat.uni-tuebingen.de/oai2d?verb=ListRecords&metadataPrefix=oai_dc - Get record (DOI: 10.57754/FDAT.00m41-m7653):
https://fdat.uni-tuebingen.de/oai2d?verb=GetRecord&metadataPrefix=oai_dc&identifier=oai:fdat.uni-tuebingen.de:00m41-m7653
Validation & Monitoring
- Verify availability:
https://fdat.uni-tuebingen.de/oai2d - Validate with the OAI-PMH Validator and DataCite’s OAI checker before go-live.
Available Metadata Formats
- Mandatory:
oai_dc: unqualified Dublin Core 1.1. - Recommended:
oai_datacite: rich DataCite 4.x metadata for datasets & software.
Resumption Tokens for Incremental Harvests
When a ListRecords or ListIdentifiers request
returns more hits than the repository’s batch size
(FDAT: 10 records), the server truncates the response and
places a <resumptionToken> element at the end.
This token is an opaque cursor; clients must reuse it
unchanged in the next request, with no other OAI-PMH parameters,
until the token comes back empty.
-
Example resumption token structure:
<resumptionToken expirationDate="2025-06-06T12:35:25Z" cursor="0" completeListSize="395"> {Resumption Token} </resumptionToken> - List all identifiers with resumption token:
https://fdat.uni-tuebingen.de/oai2d?verb=ListIdentifiers&resumptionToken={Resumption Token}